Apache Airflow® ETL Quickstart
Apache Airflow® ETL Quickstart
Welcome to Astronomer’s Apache Airflow® ETL Quickstart! 🚀
You will set up and run a fully functional Airflow project for a TaaS (Trees-as-a-Service) business that provides personalized, hyperlocal recommendations for which trees to plant in an area. This quickstart focuses on an ETL (extract-transform-load) pattern to generate tree planting recommendations for anyone from individuals to large corporations 🌲🌳🌴!
Other ways to Learn
Optionally, you can choose to use the workshop version of this quickstart with hands-on exercises in the README to practice using key Airflow features.
Time to complete
This quickstart takes approximately 15 minutes to complete.
Assumed knowledge
To get the most out of this quickstart, make sure you have an understanding of:
- Basic Airflow concepts. See Introduction to Apache Airflow.
- Basic Python. See the Python Documentation.
Prerequisites
- Homebrew installed on your local machine.
- An integrated development environment (IDE) for Python development. This quickstart uses Cursor which is very similar to Visual Studio Code.
- (Optional) A local installation of Python 3 to improve your Python developer experience.
Step 1: Install the Astro CLI
The free Astro CLI is the easiest way to run Airflow locally in a containerized environment. Follow the instructions in this step to install the Astro CLI on a Mac using Homebrew, for other installation options and operating systems see Install the Astro CLI.
-
Run the following command in your terminal to install the Astro CLI.
-
Verify the installation and check your Astro CLI version. You need to be on at least version 1.34.0 to run the quickstart.
-
(Optional). Upgrade the Astro CLI to the latest version.
Note
If you can’t install the Astro CLI locally, skip to Run the quickstart without the Astro CLI to deploy and run the project with a free trial of Astro.
Step 2: Clone and open the project
-
Clone the quickstart code from its branch on GitHub. This command will create a folder called
devrel-public-workshopson your computer. -
Open the project folder in your IDE of choice. This quickstart uses Cursor which is very similar to Visual Studio Code.
Tip
If you quickly need a new Airflow project in the future you can always create one in any empty directory by running
astro dev init.
Step 3: Start the project
The code you cloned from GitHub already contains a fully functional Airflow project. Let’s start it!
-
Run the following command in the root of the cloned folder to start the quickstart:
Info
If port 8080 or 5432 are in use on your machine, Airflow won’t be able to start. To run Airflow on alternative ports, run:
-
As soon as the project has started, the Airflow UI opens in your default browser. When running the start command for the first time this might take a couple of minutes. Note that as long as the Airflow project is running, you can always access the UI in another browser or additional tab by going to
localhost:8080. -
Click on the Dags button (1) in the Airflow UI to get to the Dags overview page to see all the DAGs contained in this project.
Step 4: Run the setup DAG
You should now see 3 DAGs. They will be paused by default, with no runs yet. In this step, you’ll run the trees_database_setup DAG to set up the database used in the ETL DAG in Step 5.
-
Click on the play button (2) of the
trees_database_setupDAG (1) to open its DAG Trigger form.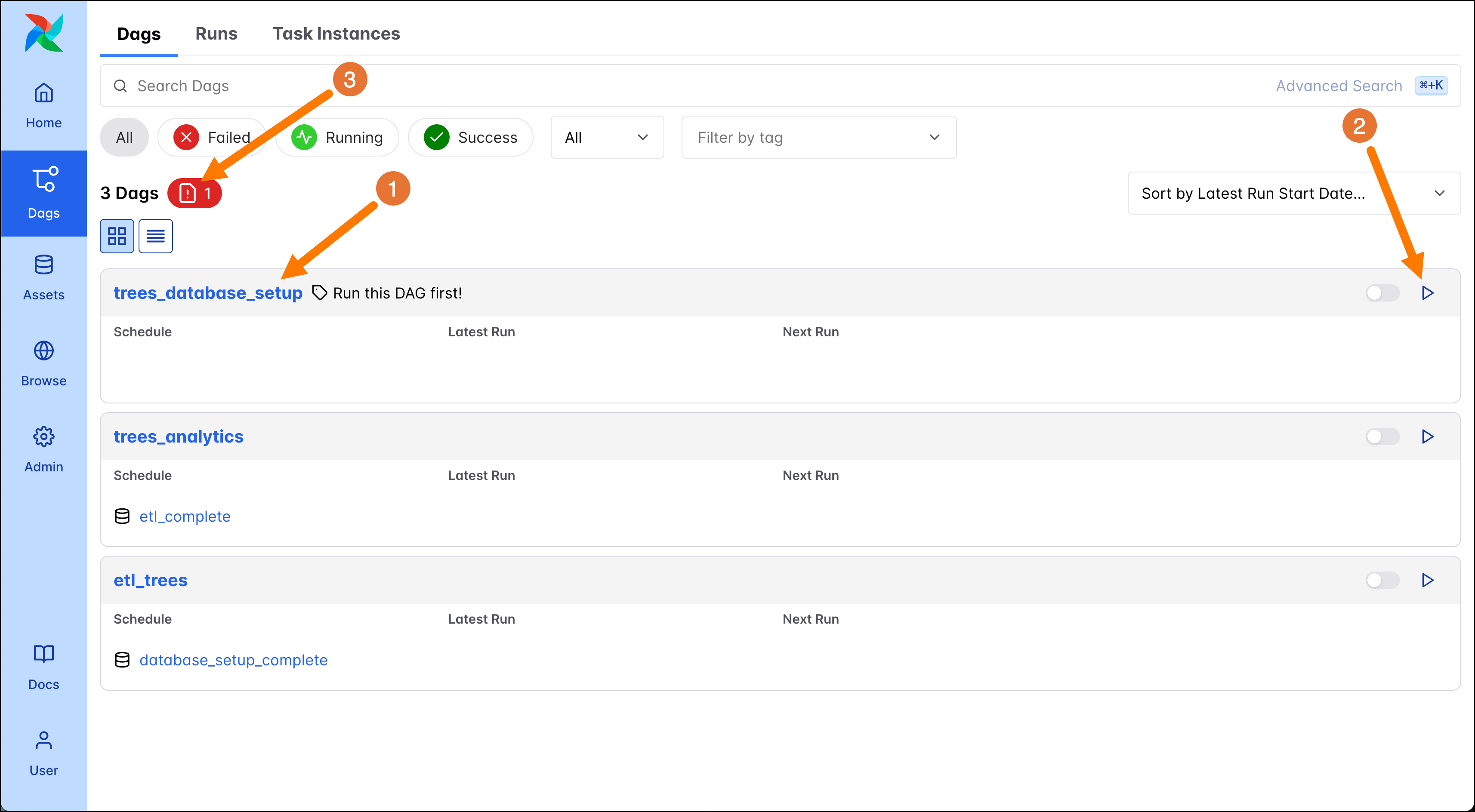
Note that there is an Import Error (3) for a fourth DAG. This DAG performs a call to a Large Language Model (LLM) to generate personalized messages based on a tree recommendation and needs a little bit more setup to use. See the Airflow Quickstart - GenAI for instructions. For this ETL quickstart you don’t have to worry about this import error; it does not affect the DAGs in the ETL pipeline.
-
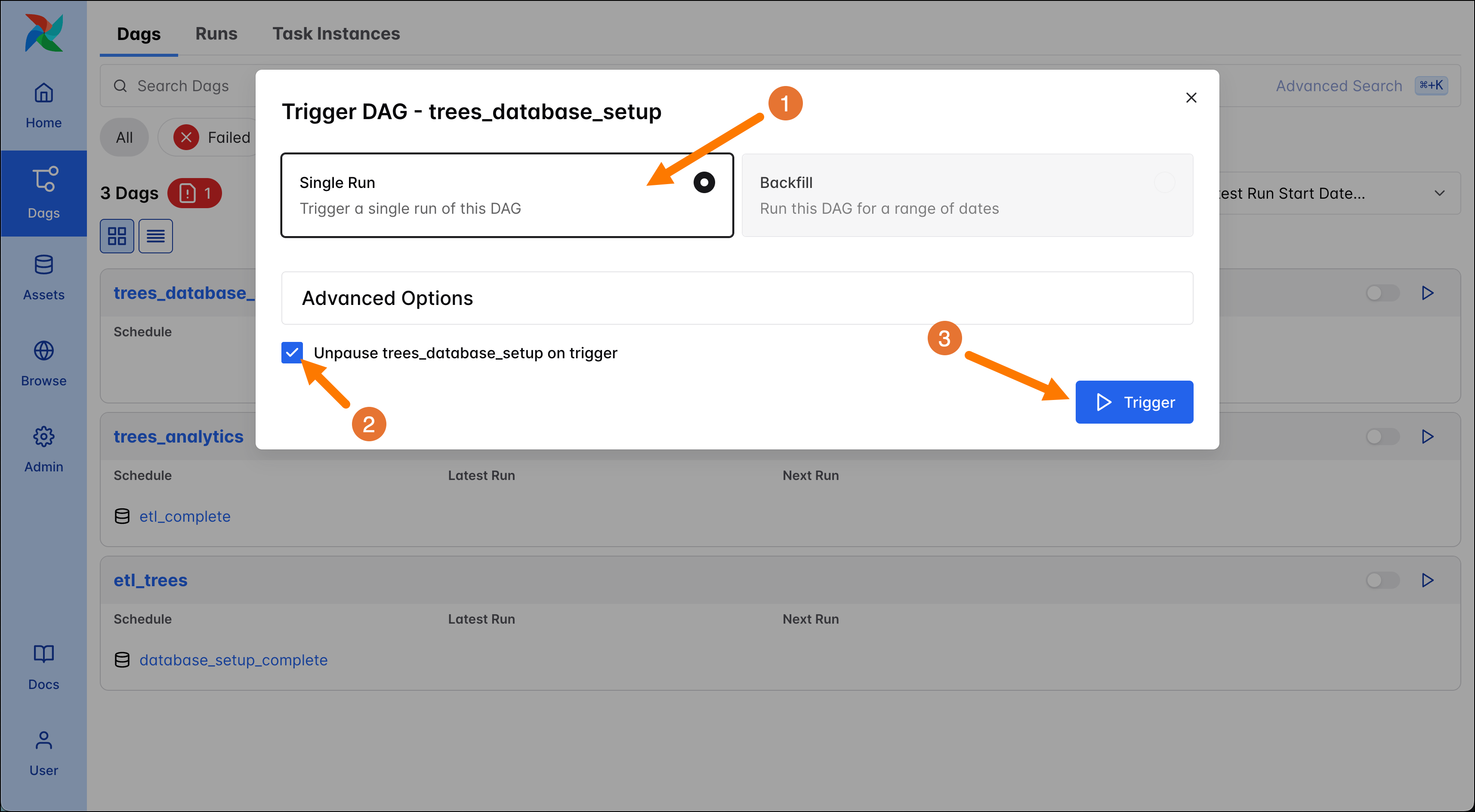
On the DAG Trigger form, make sure that Single Run (1) is selected and the Checkbox for Unpause trees_database_setup on trigger is checked (2). Then click on the blue Trigger button (3) to create a DAG run.
-
After a few seconds the DAG run should be complete and you’ll see a dark green bar in the Airflow UI (1).
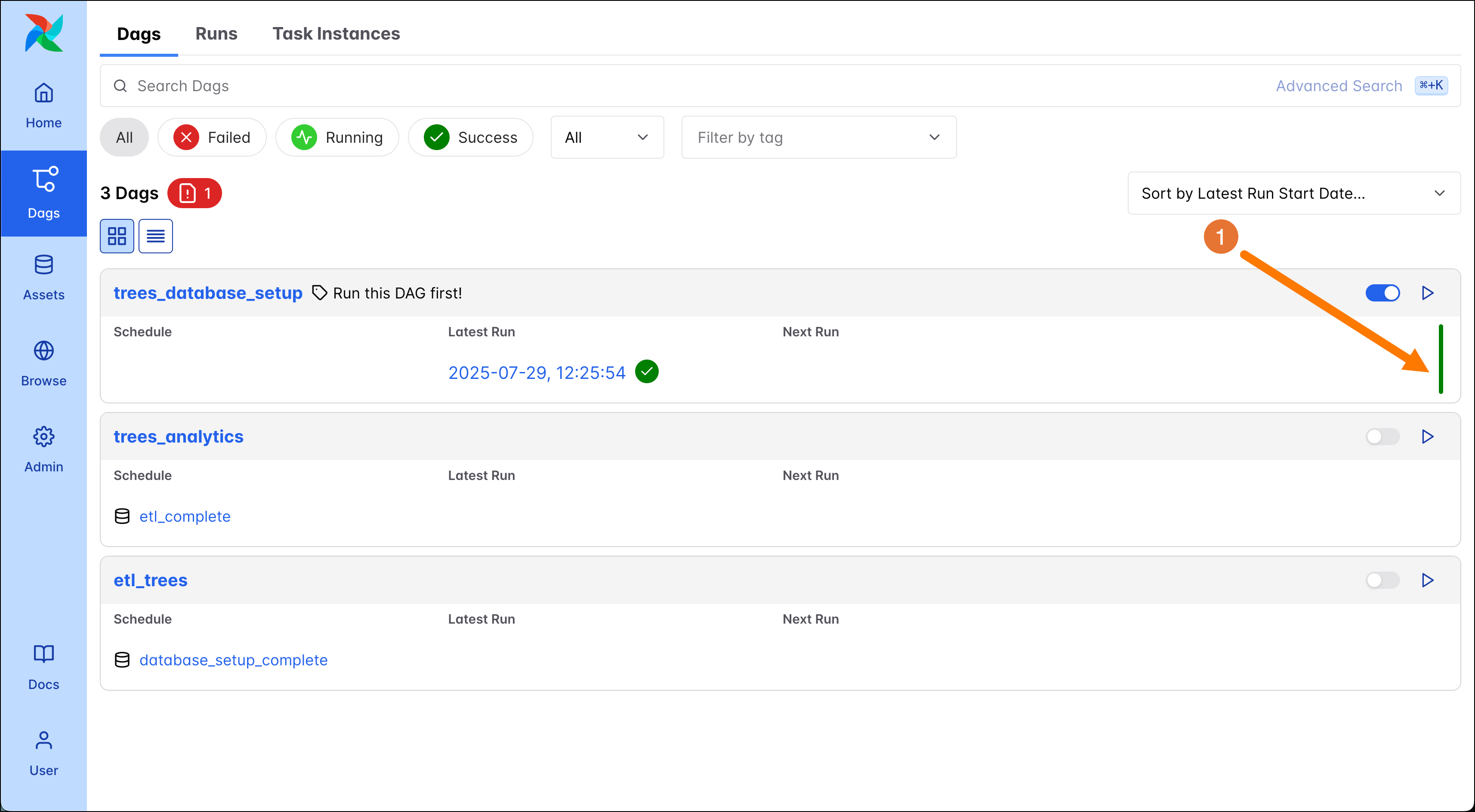
In your IDE you can open the include folder (1) to see that a new file called
trees.db(2) was created. This is the DuckDB database the ETL DAG interacts with.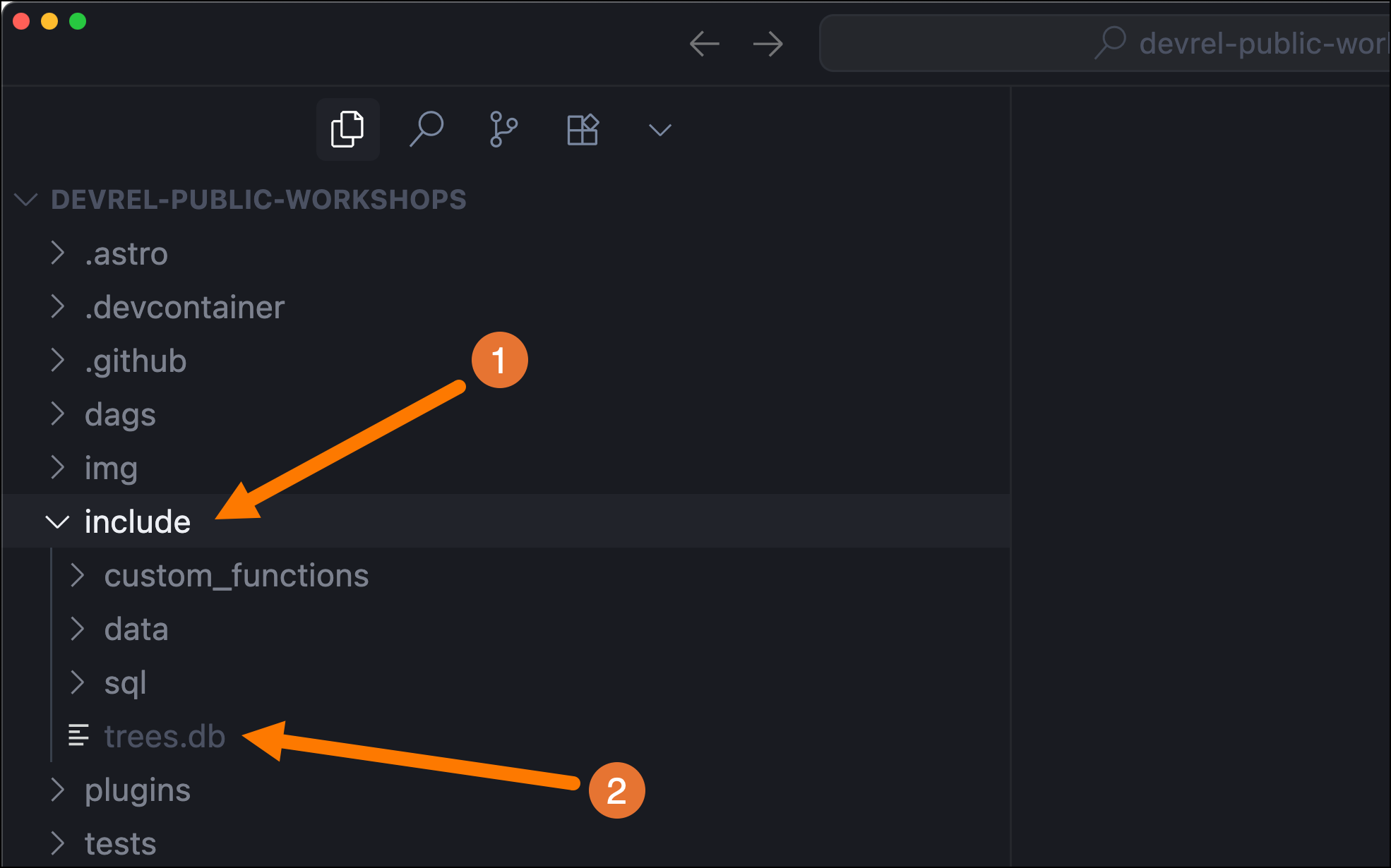
Step 5: Run the ETL DAGs
The trees_database_setup DAG created the trees.db and filled it with some sample data. Now it is time for you to run the ETL pipeline consisting of two DAGs: etl_trees, which loads an additional record to the database with tree recommendations for you, and the trees_analytics DAG which summarizes the database contents.
These two DAGs depend on each other using an Airflow Asset, which means that as soon as a specific task in the first DAG (the summarize_onboarding task in the etl_trees DAG) completes successfully, the second DAG (trees_analytics) will run automatically.
-
Unpause both DAGs by clicking their pause toggle to turn them blue (1 and 2). Unpaused DAGs will run on their defined schedule, which can be time-based (for example run once per day at midnight UTC) or data-aware like in this example. Next, open the DAG trigger form for the
etl_treesDAG by clicking on its play button (3).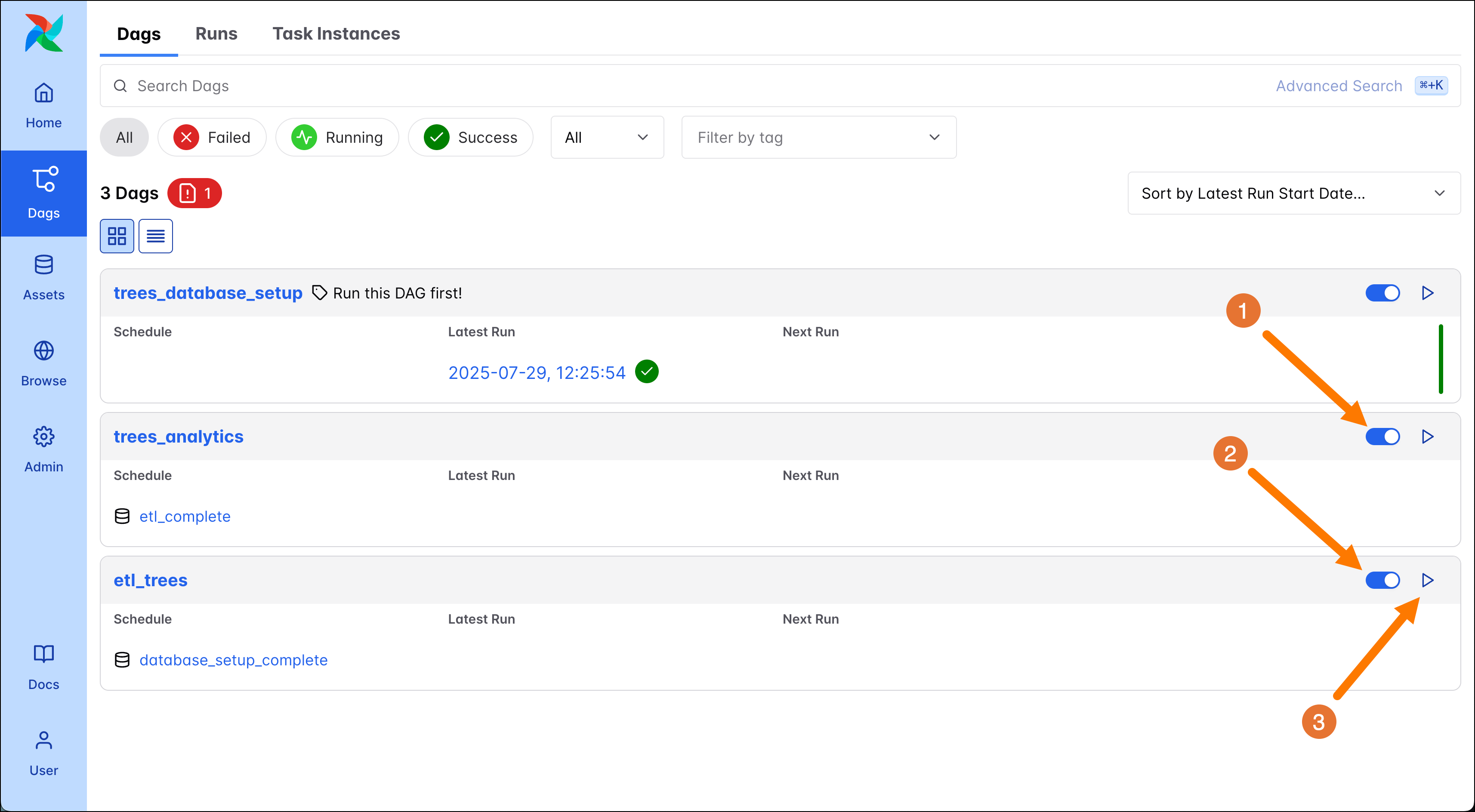
-
The
etl_treesDAG runs with params. If the DAG runs based on its schedule the given defaults are used, but on a manual run, like right now, you can provide your own values. Enter your name (1) and your location (2), then trigger (3) a DAG run.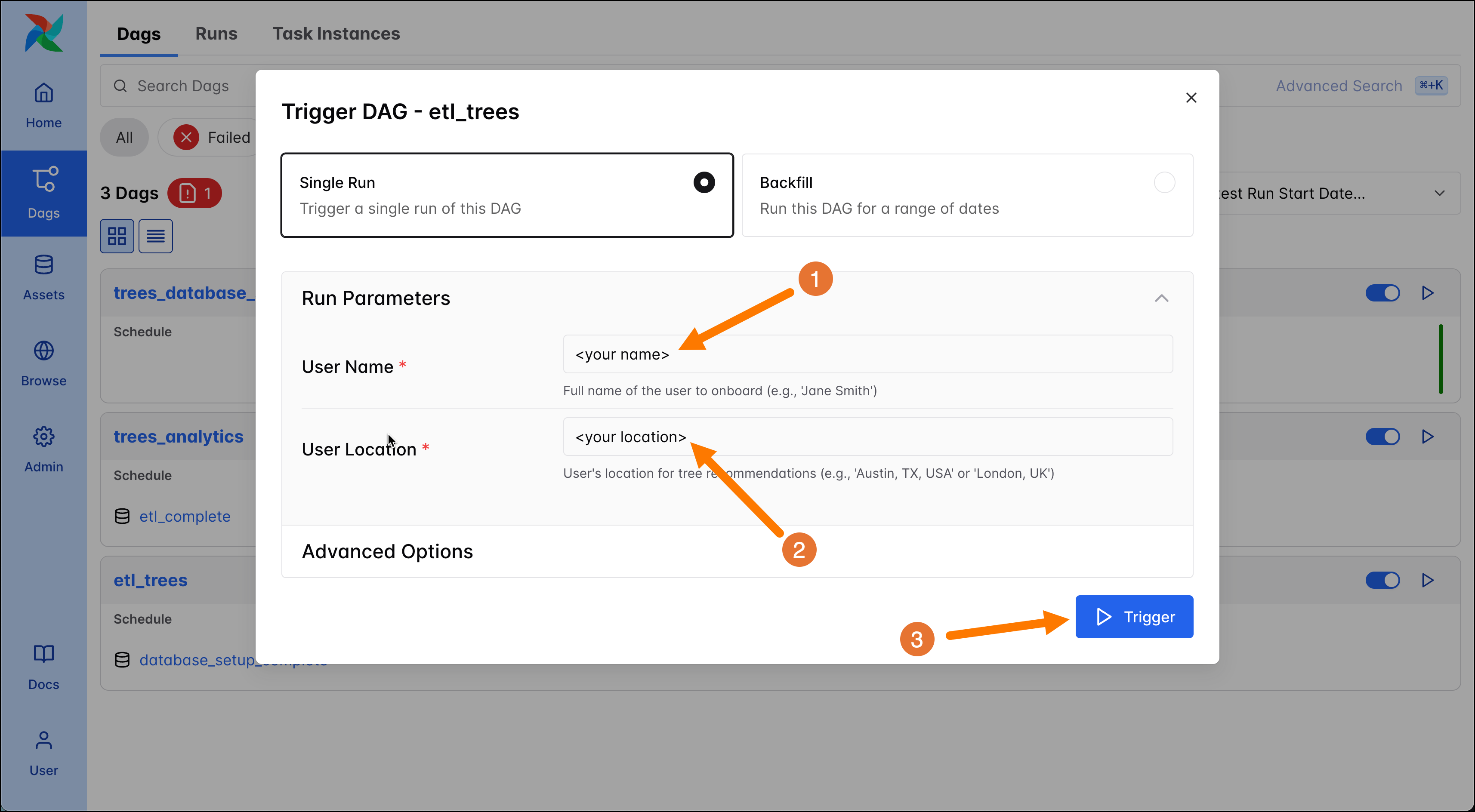
-
After 10-20 seconds both the
etl_treesand thetrees_analyticsDAG have completed successfully (1 and 2).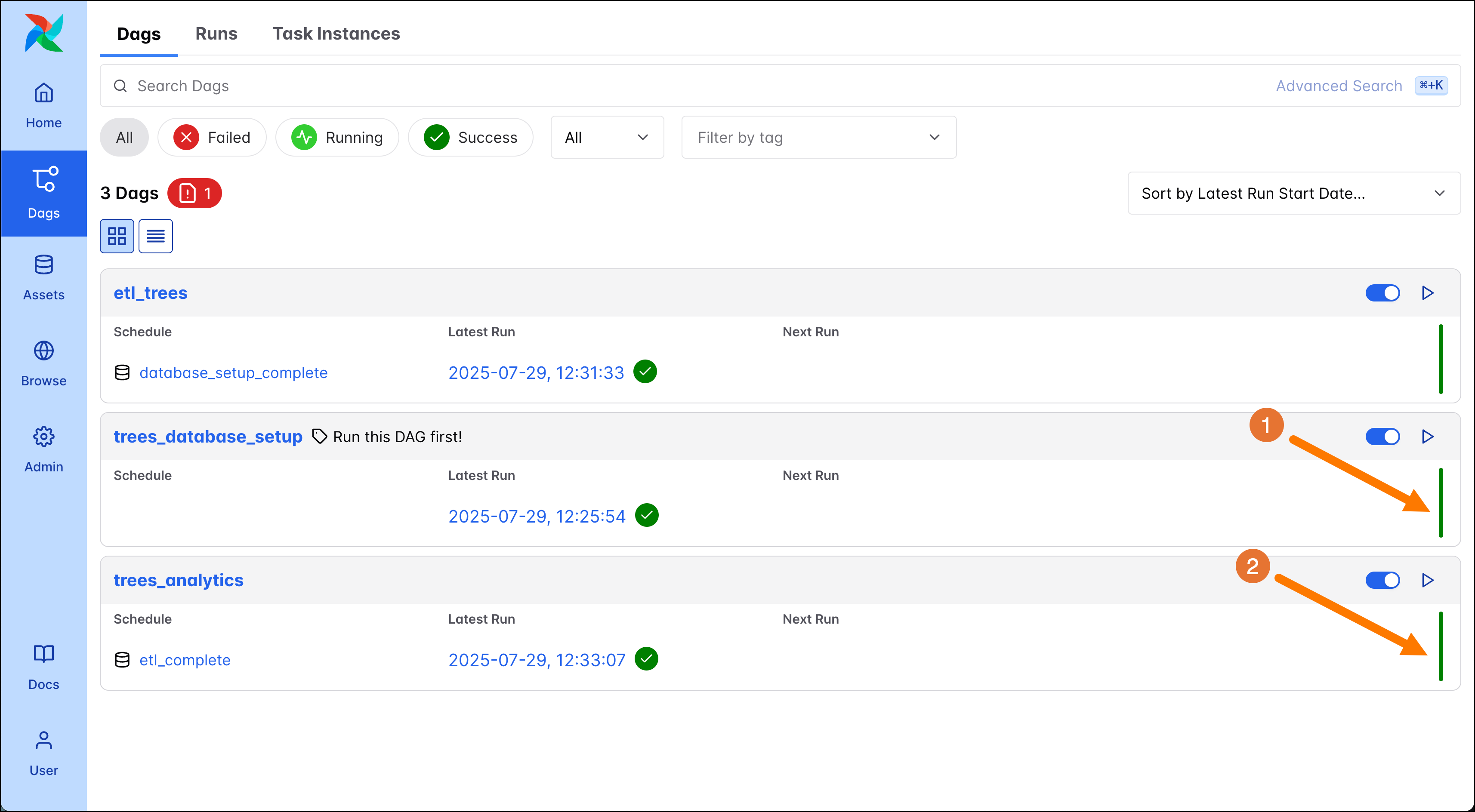
Step 6: Explore the ETL DAG
Let’s explore the ETL DAG in more detail.
-
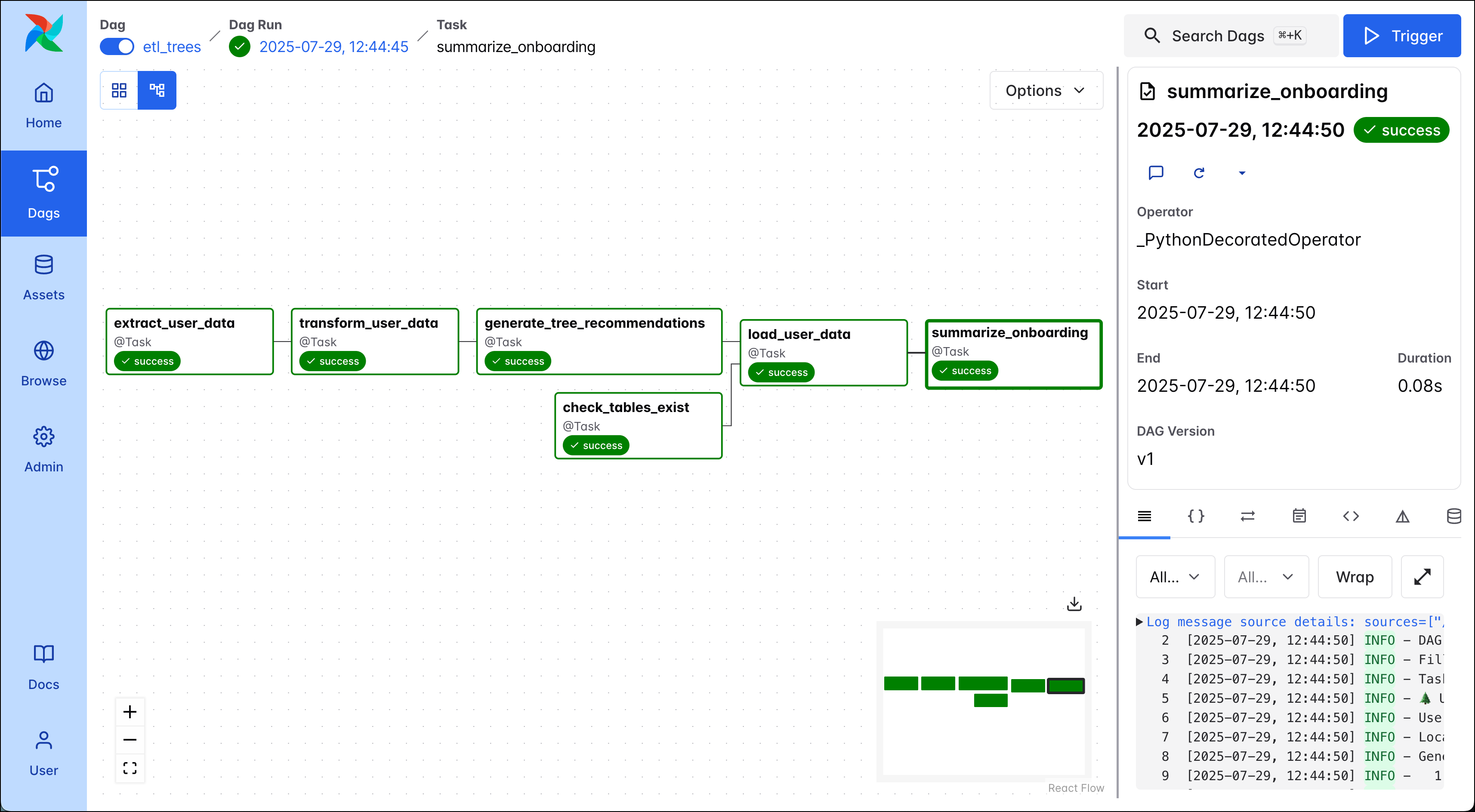
Click on the DAG name to get to the DAG overview. From here you can access a lot of detailed information about this specific DAG. To navigate to the logs of individual task instances, click on the squares in the grid view. Open the logs for the
summarize_onboardingtask (1) to see your tree recommendations!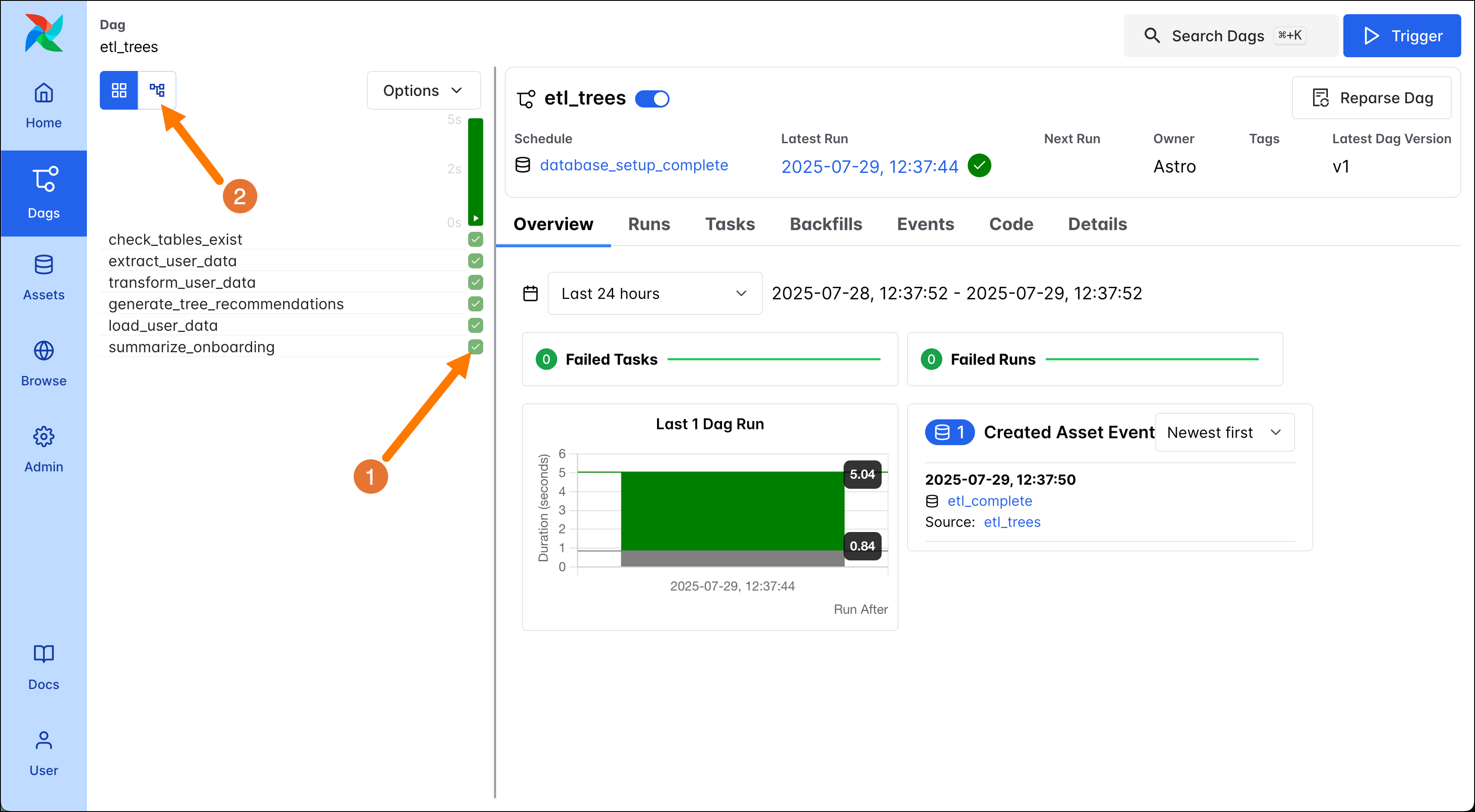
-
Next, to view the dependencies between your DAGs you can toggle between the Grid and Graph view in the top left corner of the DAG overview (2). Each node in the graph corresponds to one task. The edges between the nodes denote how the tasks depend on each other, and by default the DAG graph is read from left to right. The code of the DAG can be found by viewed by clicking on the Code tab (1).
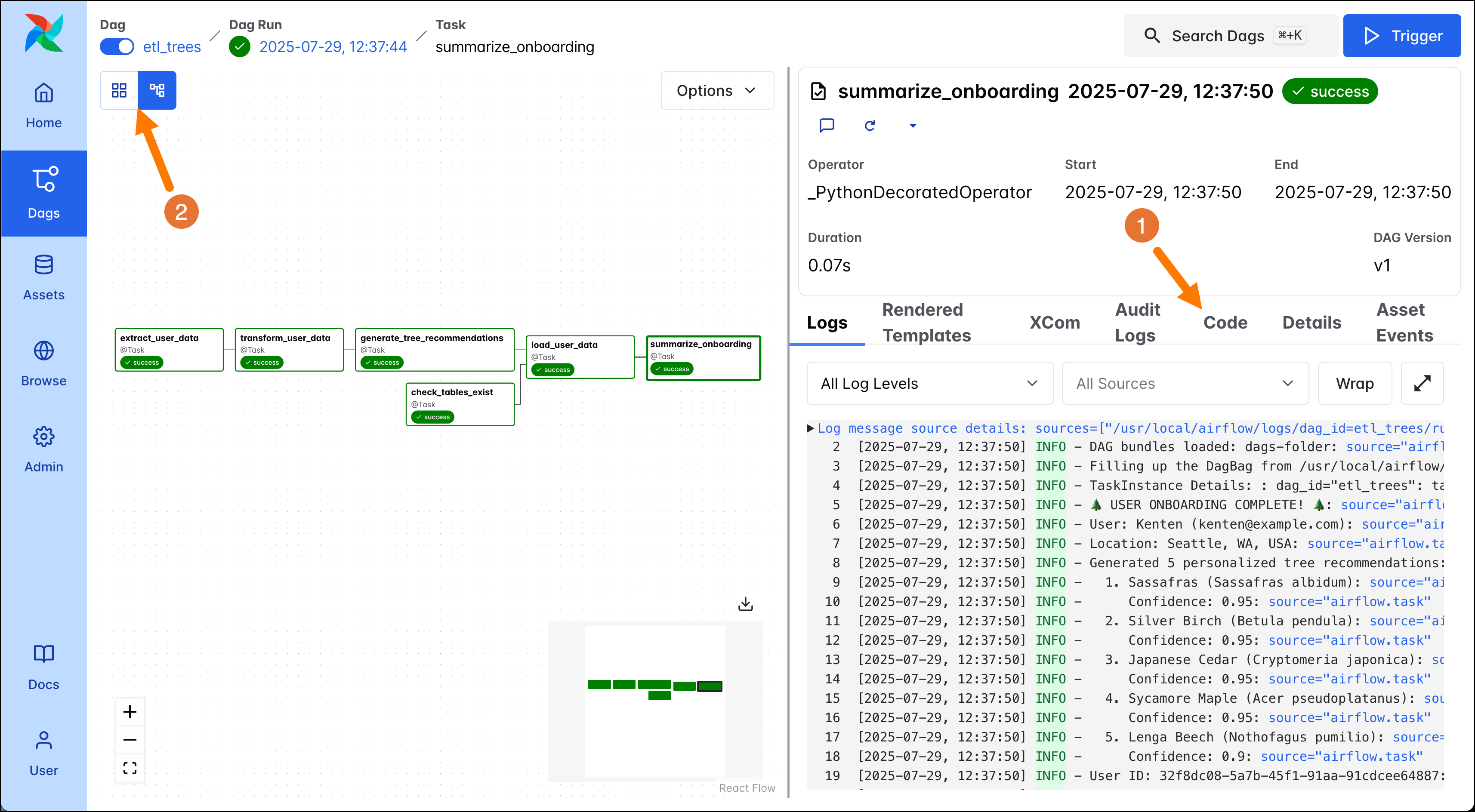
In the screenshot above you can see the graph of the ETL DAG, it consists of 6 tasks:
extract_user_data: This task extracts user data. In this quickstart example the DAG uses the data entered in the DAG Trigger form, the name and location of one user. In a real-world use case, it would likely extract several users’ records at the same time through calling an API or reading from a database.transform_user_data: This task uses the data the first task extracted and creates a comprehensive user record from it using modularized functions stored in theincludefolder.generate_tree_recommendations: The third task generates the tree recommendations based on the transformed data about the user.check_tables_exist: Before loading data into the database, this task makes sure that the needed tables exist in the database.load_user_data: This task loads data into the database, it can only run after bothgenerate_tree_recommendationsandcheck_tables_existhave completed successfully.summarize_onboarding: The final task summarizes the data that was just loaded to the database and prints it to the logs.
-
Let’s check out the code that defines this DAG by clicking on the Code tab. Note that while you can view the DAG code in the Airflow UI, you can only make changes to it in your IDE, not directly in the UI. You can see how each task in your DAG corresponds to one function that has been turned into an Airflow task using the
@taskdecorator.
Note
The
@taskdecorator is one of several options for defining your DAGs. The two other options are using traditional operators or the@assetdecorator.
-
The second DAG in this ETL pipeline,
trees_analytics, is defined with the@assetdecorator, a shorthand to create one DAG with one task updating one Asset.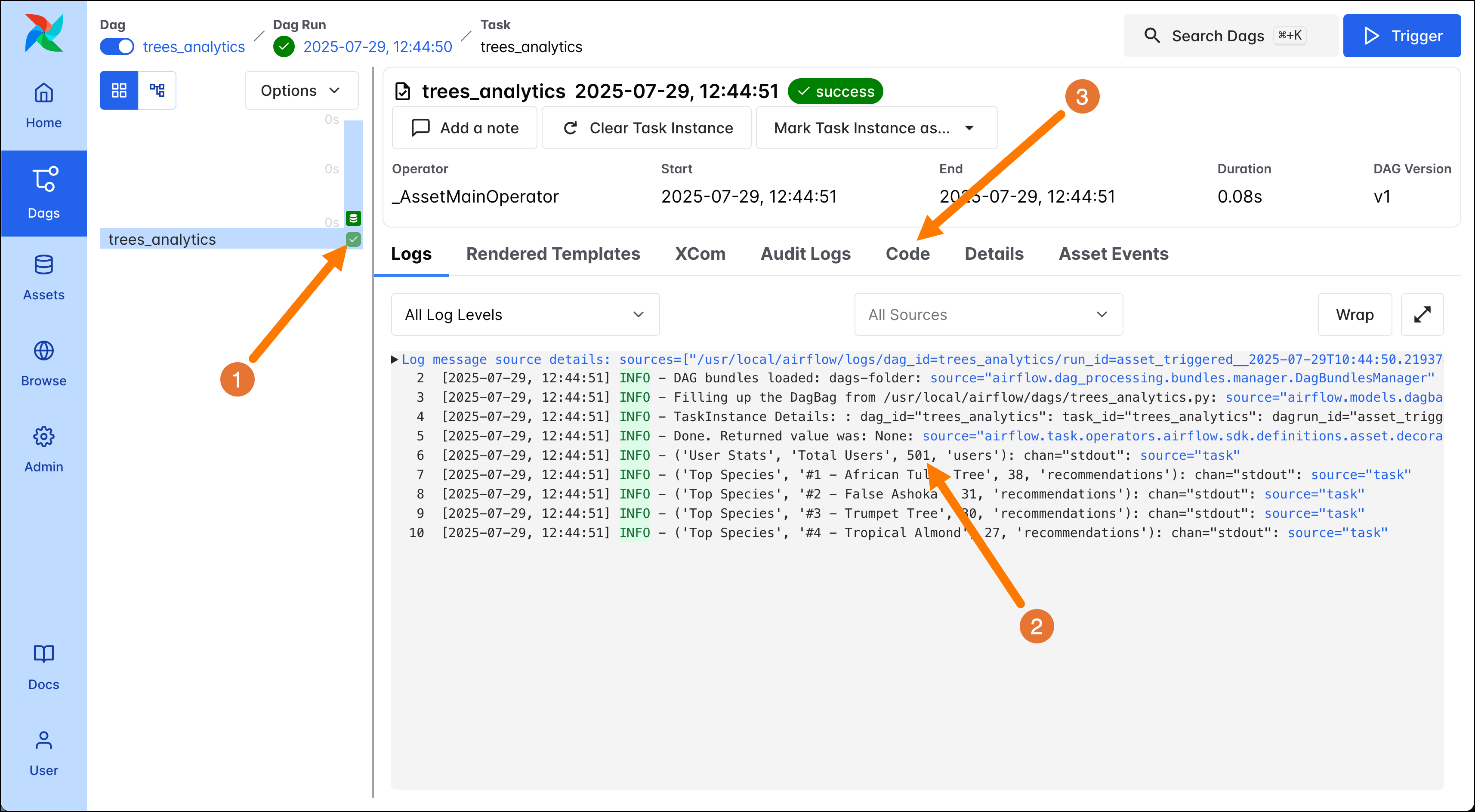
Click on the DAG name in the DAG overview page, and then on the square for the
trees_analyticstask (1) to view the logs containing summary analytics about your tree recommendations. Since the setup DAG adds 500 users to the database, and you just added yourself with the ETL DAG, you should see501users in the log output (2). Viewing the DAG code (3) you can see how the@assetdecorator quickly turns a Python function into an Airflow DAG with one task. -
(Optional). Make a small change to your DAG code, for example by adding a print statement in one of the
@taskdecorated functions. After the change has taken effect, run your DAG again and see the added print statement in the task logs.
Tip
When running Airflow with default settings, it can take up to 30 seconds for DAG changes to be visible in the UI and up to 5 minutes for a new DAG (with a new DAG ID) to show up in the UI. If you don’t want to wait you can run the following command to parse all existing and new DAG files in your
dagsfolder.
Step 7: Deploy your project
It is time to move the project to production!
-
If you don’t have access to Astro already, sign up for a free Astro trial.
-
Create a new Deployment in your Astro workspace.
-
Run the following command in your local CLI to authenticate your computer to Astro. Follow the login instructions in the window that opens in your browser.
-
Run the command to the deploy to Astro.
-
Once the deploy has completed, click the blue
Open Airflowbutton on your Deployment to see the DAGs running in the cloud. Unpause all 3 DAGs in your Astro environment and run thetrees_database_setupDAG manually. This will trigger a run of all 3 DAGs since they depend on each other using anAssetschedule. -
Check the logs of the
summarize_onboardingtask in theetl_treesDAG to see the tree recommendations generated for the default user set in the Airflow params. -
(Optional) Change the default user and default location by adding two environment variables to your Astro Deployment. In the Astro UI click on the
Environmenttab (1) for your Deployment and add your own values forUSER_NAMEandUSER_LOCATION.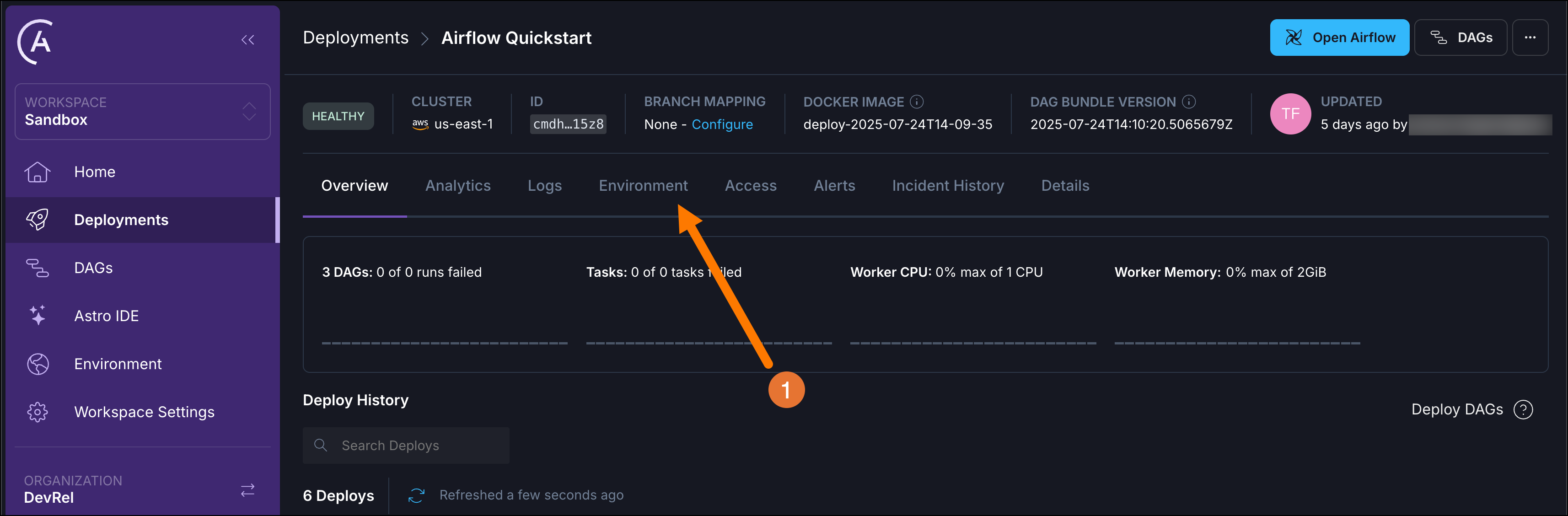
-
(Optional) After the new environment variables have synced to your Astro Deployment (this can take a few minutes), run the
etl_treesmanually. The default suggestions in the DAG Trigger form are now based on your own values and you’ll get another set of personal tree recommendations, this time on Astro!
Next steps
Awesome! You ran an ETL pipeline locally and in the cloud. To continue your learning we recommend the following resources:
- If you are curious about the DAG currently showing as an import error and want to learn how to use Airflow for GenAI workflows, check out the Airflow GenAI quickstart.
- To get a structured video-based introduction to Apache Airflow and its concepts, sign up for the Airflow 101 (Airflow 3) Learning Path in the Astronomer Academy.
- For a short step-by-step walkthrough of the most important Airflow features, complete our Airflow tutorial.
Run the quickstart without the Astro CLI
If you cannot install the Astro CLI on your local computer, you can still run the pipeline in this example.
-
Sign up for a free trial of Astro.
-
Create a new Deployment in your Astro workspace.
-
Fork the Airflow quickstart repository to your GitHub account. Make sure to uncheck the
Copy the main branch onlybox!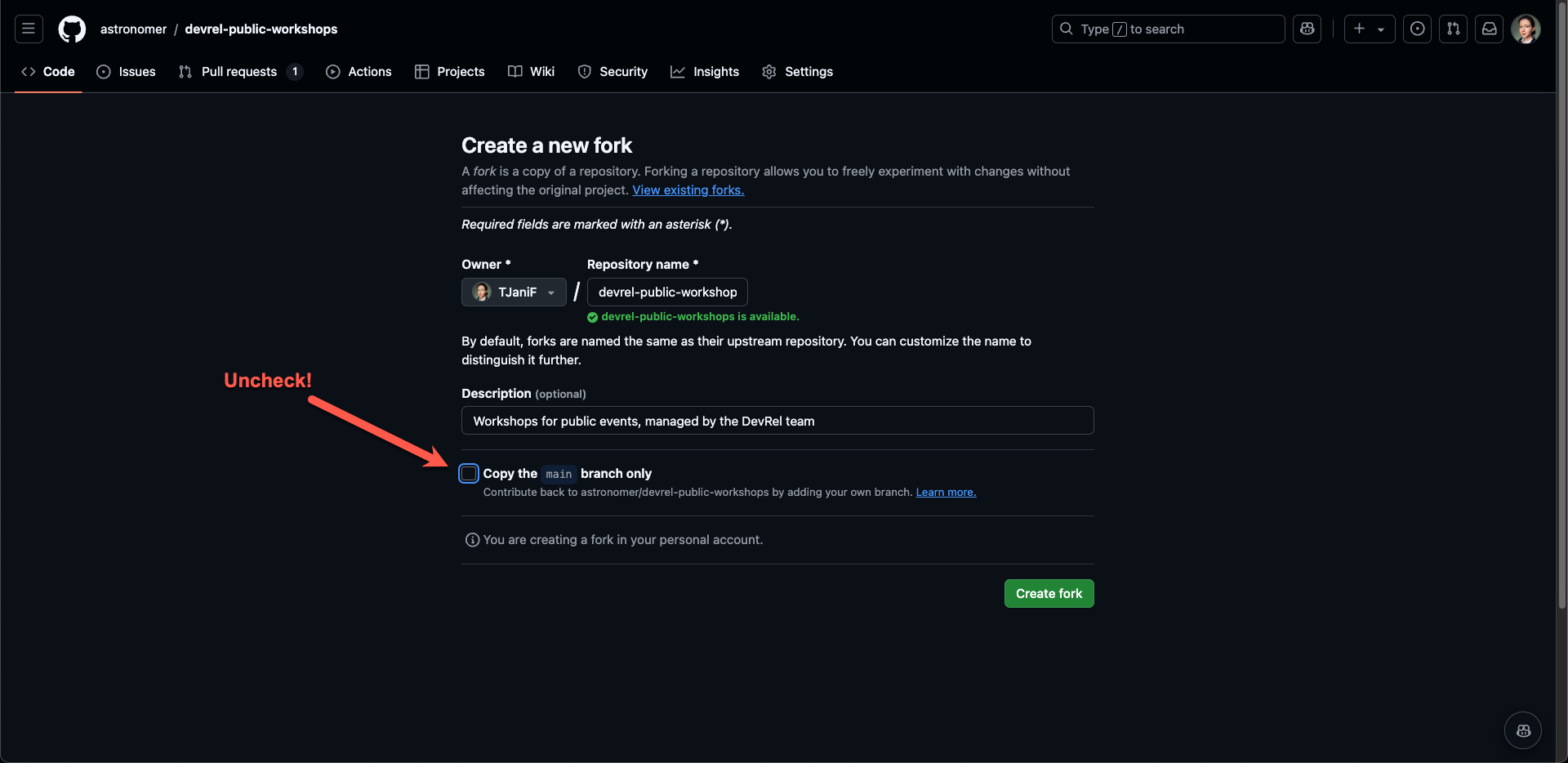
-
Set up the Astro GitHub integration to map your Deployment to the
airflow-quickstart-completebranch of your forked repository. -
Select Trigger Git Deploy from the More actions menu in your Deployment settings to trigger the first deploy for the mapped repository.
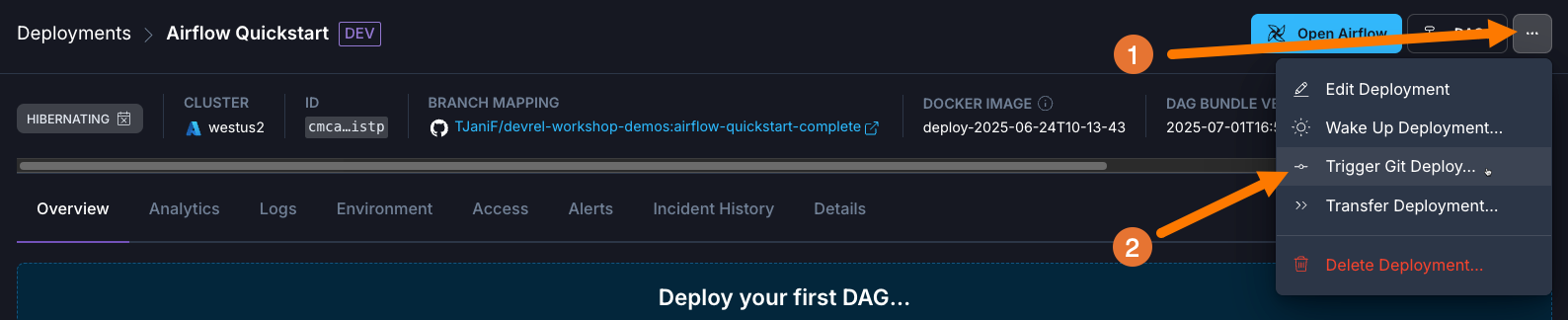
-
Once the deploy has completed, click the blue
Open Airflowbutton on your Deployment to see the DAGs running in the cloud. From here you can jump back to Step 4 and complete the quickstart, skipping over the deploy instructions in Step 7, since you already deployed your project!