3 Ways to Extract Data Lineage with Airflow
11 min read |
This article explores three different ways you can extract data lineage events from your Airflow pipelines using OpenLineage, an open-source standard for collecting and analyzing lineage metadata.
Throughout this piece we use Astronomer’s own implementation of OpenLineage in Astro — a fully managed cloud orchestration platform, powered by Apache Airflow® — to demonstrate how these methods work, but Astro isn’t required to reap the rewards. Because OpenLineage is completely open, and because Astro runs on open-source Airflow, anyone can use the methods described in this article to extract lineage events from their Airflow tasks and persist them to a supported lineage backend, such as Marquez, which is the reference implementation of the OpenLineage specification.
The difference, essentially, is that with a fully managed service like Astro you get OpenLineage support right out of the box: your Airflow operators and OpenLineage extractors, the observability backend you use to aggregate and analyze lineage metadata, and a selection of analytic views are all pre-configured for you. With open-source OpenLineage, on the other hand, you need to set up your own lineage backend, configure your OpenLineage extractors and/or Airflow operators, and, optionally, build your own analytic views.
Using Out-Of-The-Box Extractors for Airflow Operators
When you deploy your Airflow DAG on Astro, the deployment comes with OpenLineage installed and configured to emit data lineage events to a data observability backend. The following Airflow Operators emit OpenLineage events when used in a DAG:
- BigQueryOperator
- SnowflakeOperator
- PostgresOperator
- MySqlOperator
- SQLColumnCheckOperator
- SQLTableCheckOperator
- GreatExpectationsOperator
- PythonOperator
For example, consider a DAG that uses the PostgresOperator to schedule database operations with SQL:
init_course_r = DemoPostgresOperator(
task_id='init_course_r',
postgres_conn_id='astro_registry_db',
sql='''
CREATE TABLE IF NOT EXISTS COURSE_REGISTRATIONS (
CREATE_DATE DATE,
COURSE_ID NUMBER,
COURSE_NAME TEXT,
SIGNUP_URL TEXT,
NUM_STUDENTS NUMBER,
TOTAL_REVENUE NUMBER
);
'''
)
init_course_rWhen the task init_course_r is running, a PostgresExtractor is invoked. The extractor creates a pair of lineage events that are sent to Astro’s lineage backend.
These events provide the raw data that’s used to create a visual lineage graph of your pipeline in the Astro UI’s “Lineage” tab. Astro's Lineage tool gives you real-time observations of lineage events — as opposed to static lineage generated by parsing source code — and it can receive metadata from many common pipeline tools and frameworks out-of-the-box.
While tool-agnostic lineage observability might seem like a magic trick, the magic in this case is enabled by OpenLineage, which uses extractors, listeners, and facets to make that “magic” happen.
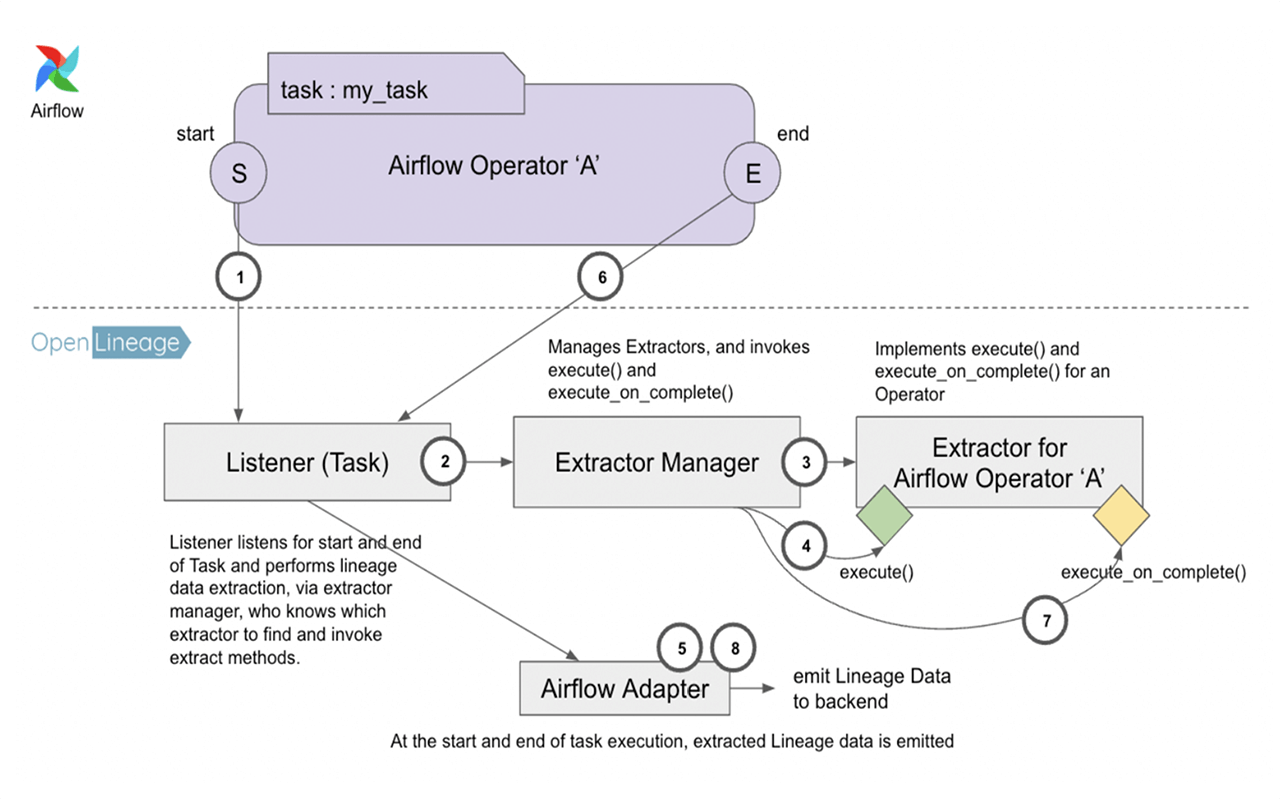
Figure 1: A look at how OpenLineage’s Listener, Extractor Manager, and Extractor work together.
In Figure 1 above, there are three major OpenLineage constructs at work: the Listener, which is the connecting piece between OpenLineage and Airflow, the Extractor Manager, which is responsible for identifying the correct extractor to use, and the Extractor, described in detail below.
The OpenLineage Extractor is analogous to the Airflow Operator: it’s a unit of work in OpenLineage that takes the relevant input and output data from an operator, creates OpenLineage data facets, and sends those facets to be displayed in the data observability backend.
Each extractor maps to a specific set of operators via the get_operator_classnames() class method. This is how the Extractor Manager finds the appropriate extractor in Step No. 3 (see Figure 1). The extractors all inherit from a BaseExtractor, which defines a few abstract methods, most importantly execute() and execute_on_complete().
After the DAG run is finished, Astro users will find lineage data by going to the Lineage tab in the Astro UI and entering the name of a dataset. For example, to see the lineage graph for the dataset created in the previous code block, you would enter “COURSE_REGISTRATIONS” in the search field.

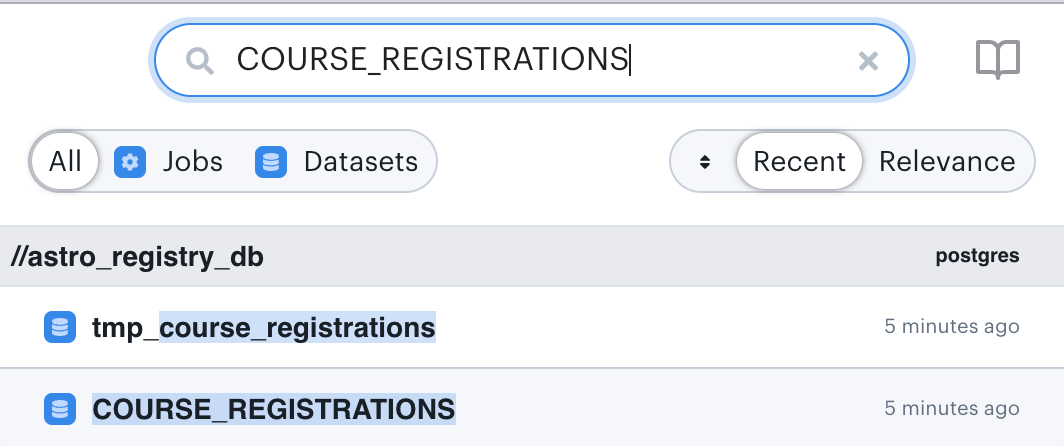

Figure 2: This concise visual expression of the flow of data through a pipeline uses arrows and nodes to represent input and output datasets (the stacked disc icons) along with the jobs (the gear icons) that create or modify them.
Read more about data lineage in Astro.
Using Custom Extractors for Airflow Operators
As we saw above, Astro supports a number of operators for extracting and emitting data lineage events out of the box. However, there may be cases where you’ll need to develop custom Airflow operators that require their own specific extractors. For example, DAG authors need to create custom Airflow operators whenever they want to work with custom-built apps, or, alternately, with legacy software that is no longer in widespread use. Authors must also create custom OpenLineage extractors if they want to collect the lineage events emitted by their operators.
Here’s an example of a custom Extractor that extracts dataset-related information from a PythonOperator. We’ve chosen to extend the PythonOperator for this example due to its simplicity. To illustrate how custom extractors can pass along data from the task's execution, our custom Extractor will convert input arguments given to the PythonOperator into properly-formatted input Dataset objects.
Admittedly, using a PythonOperator to produce an input and output dataset in this way may not be useful. However, this straightforward example shows how a custom extractor can be implemented for situations where no pre-built extractor is available.
To use this custom Extractor, we’ll extend the functionality of the existing PythonOperator and create a new operator, MyPythonOperator, as shown below:
class MyPythonOperator(PythonOperator):
def __init__(
self,
**kwargs
) -> None:
super().__init__(**kwargs)This operator doesn’t have any new features, but since the Extractor will be triggered based on the operator’s name, we need to distinguish it from the original PythonOperator.
We’ll provide this extractor to the environment variable OPENLINEAGE_EXTRACTORS so that Airflow can distinguish which extractor to invoke for each operator. The custom Extractor won’t work without this setting:
OPENLINEAGE_EXTRACTORS=demo_extractor.MyPythonExtractorOne important thing to note about the new Extractor is its class method get_operator_classnames(), which returns the list of operators the new Extractor is looking to extract from:
@classmethod
def get_operator_classnames(cls) -> List[str]:
return ['MyPythonOperator']The correct name of the class (in this case, MyPythonOperator) must be provided for it to be triggered. There can be multiple operators in the list. For example, if we want this extractor to override the existing extractor for the PythonOperator, we can simply do this:
@classmethod
def get_operator_classnames(cls) -> List[str]:
return ['MyPythonOperator', ‘PythonOperator’]When the PythonOperator is executed, the new Extractor will be used instead of the default.
Ultimately, that's how the DAG source code will look like.
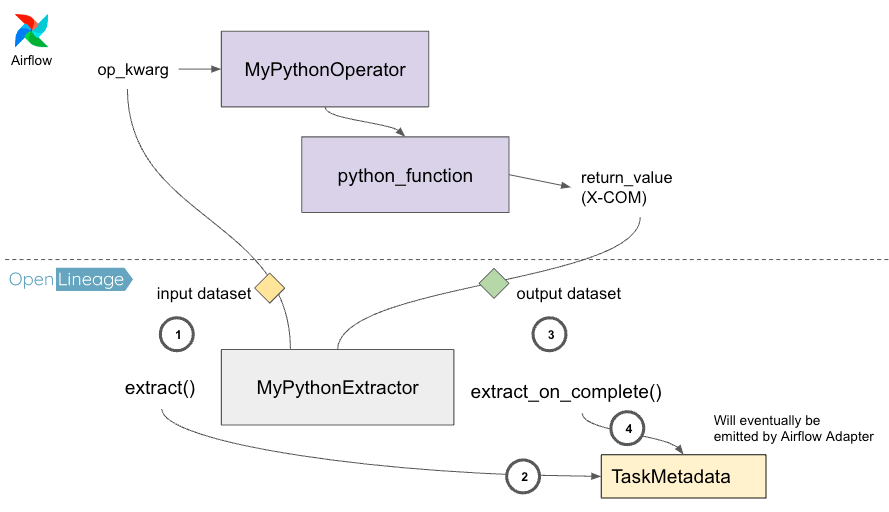
Figure 3: The custom OpenLineage extractor, MyPythonExtractor, collects the lineage events, TaskMetadata, emitted by a custom Python operator MyPythonOperator.
When MyPythonOperator is running, the Extractor checks if the class name of the operator (MyPythonOperator) has a defined matching extractor. It will find that ‘MyPythonExtractor’ is registered via the environment variable and the Extractor will invoke the extract() and extract_on_complete() methods at the beginning and end of the operator’s execution. The methods will derive lineage data in the form of a TaskMetadata object to be emitted to Astro’s data observability backend.
Running the DAG will produce the Lineage Graph, which now has an input dataset as the input to the test-operator job, and an output dataset as the job’s output (Figure 4). You can search the Lineage Graph for jobs and datasets if you know all or part of their names.

Figure 4: The resultant lineage graph.
When you click on the input dataset, a “Description” field will be visible that contains the op_kwargs parameter (“x” : “Apache Airflow®”) that we provided to our operator in our DAG:
t1 = MyPythonOperator(
task_id='test-operator',
python_callable = python_operator,
**op_kwargs = {"x" : "Apache Airflow®"},**
provide_context=True
)Our custom Extractor has converted that data into Dataset format, displaying it like this in the Lineage tab:
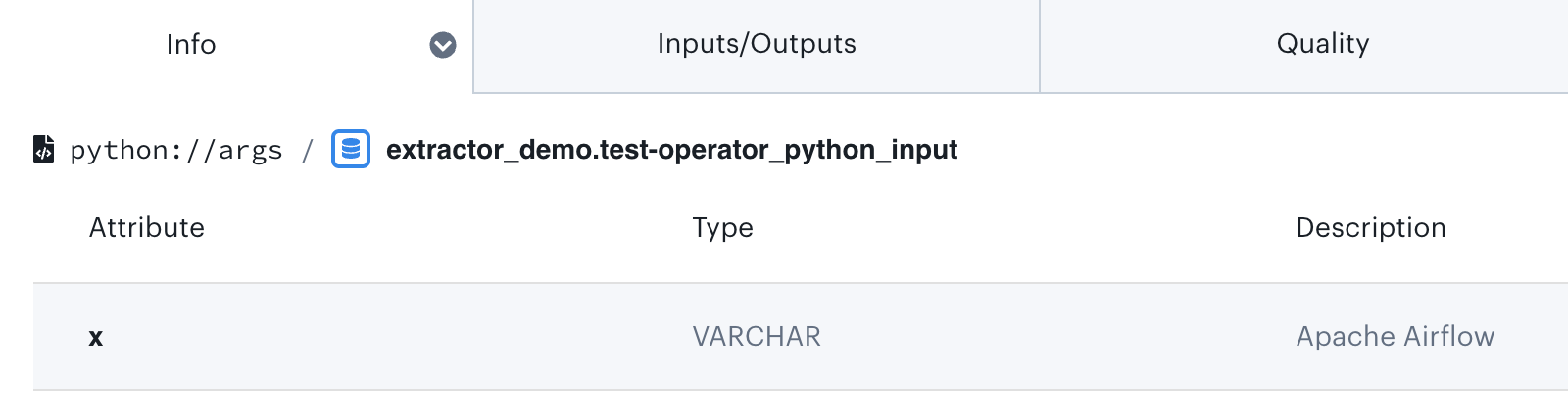
Figure 5: View of the resultant dataset in the Astro Lineage tab.
Similar to how the input dataset was implemented, the extract_on_complete() method has code that detects whether the latest task instance’s XCom has a value. The method produces the output data according to what the operator returns:
def python_operator(x):
print(x)
**return "Hello"**This is displayed as an output dataset:
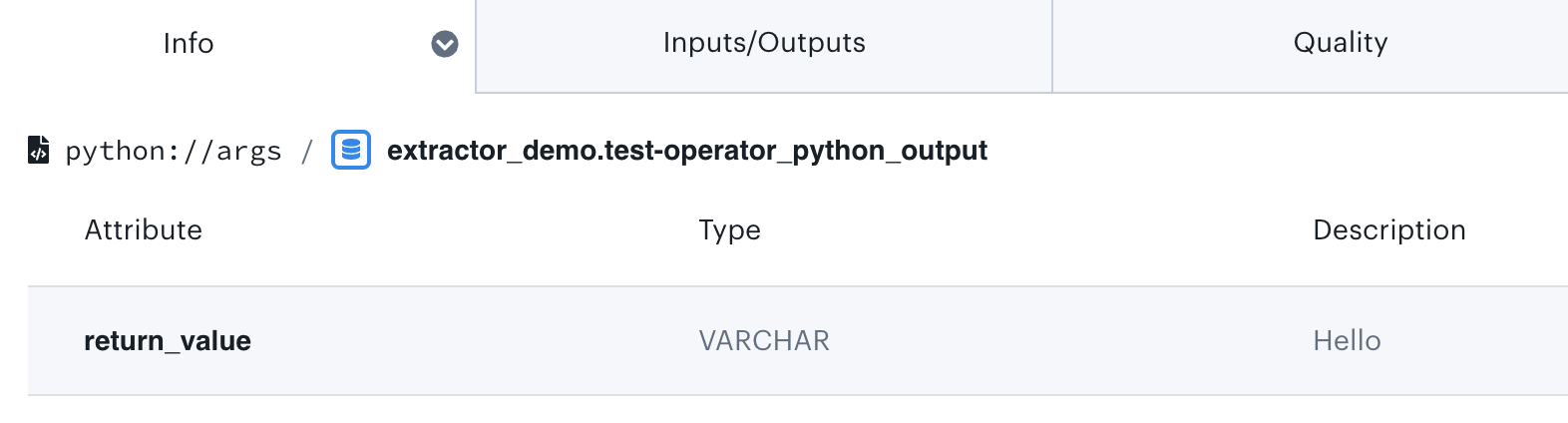
Figure 6: View of the updated dataset in the Astro Lineage tab, with the dataset description reflecting the most recent change.
Using Inlets and Outlets to Manually Set Data Lineage in Airflow Operators
If you don’t need an entirely custom extractor, there’s another option that can give you a similar result. Operator inlets and outlets are new features recently added to Airflow that add data-lineage-related items without the burden of developing and deploying custom extractors.
Currently the Table entity is the only type of lineage-related entity that can be made known to an operator.
Let’s explore how to set an inlet and outlet for a simple PythonOperator.
If you deployed this DAG to Astro, you would see the following DAG graph, which will run the PythonOperator in the task test-operator:

Figure 7: Airflow Graph view of our DAG.
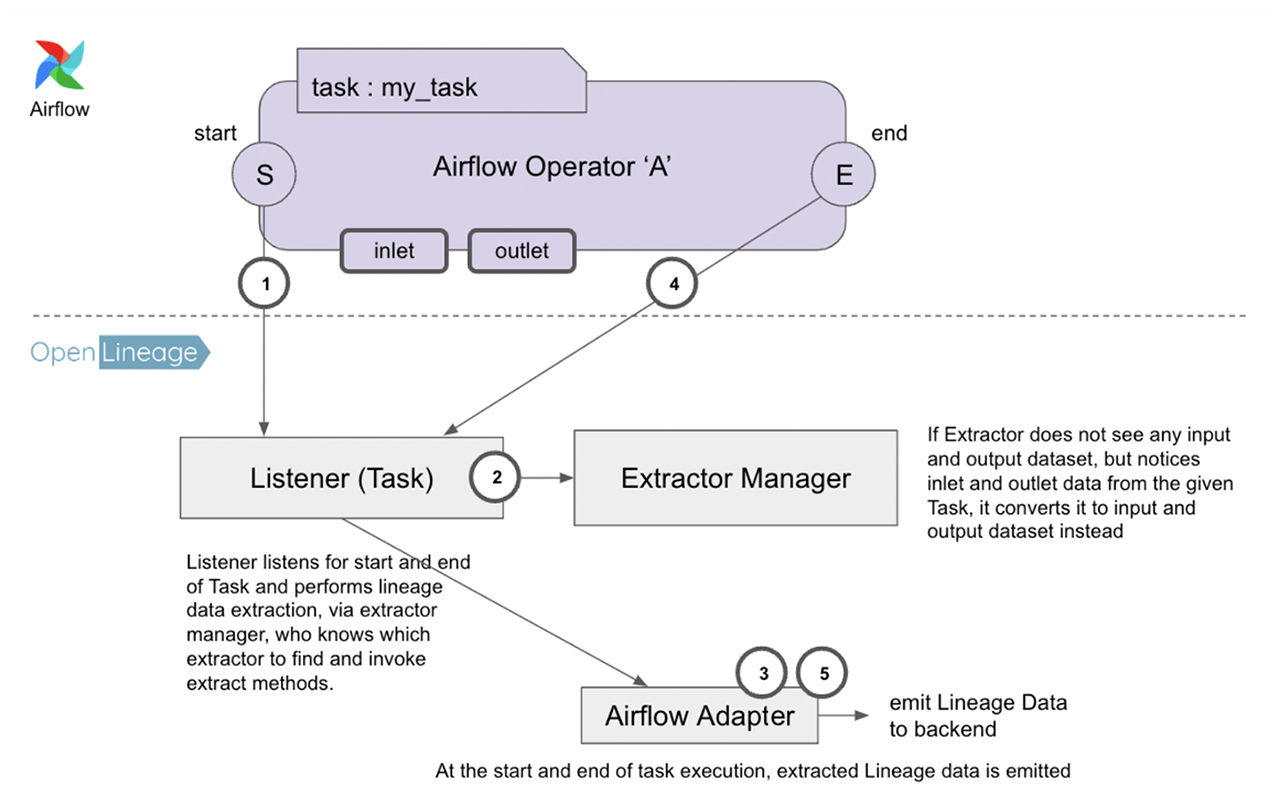
Figure 8: The Listener uses the inlets and outlets specified in Airflow Operator A to extract lineage events, persisting them to an OpenLineage-compliant backend.
This feature does not require the use of extractors, but the extractor manager checks whether the task has manually set inlets and outlets. If no input or output metadata exist, the extractor manager will use them to generate lineage events instead.
When the operator is running, the OpenLineage base extractor checks to see if the operator has any inlets and outlets, and, when they exist, it produces events for input and output data for the operator that appear in the Lineage tab. Here’s an example:
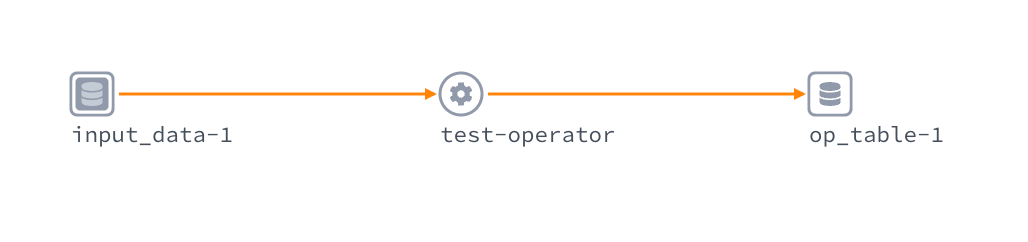
Figure 9: The resultant lineage graph.
In a case where the extractor produces its own input and output datasets, the extractor overrides the inlets and outlets in the operator. In other words, setting the inlets and outlets is only meaningful when there’s no specific extractor for the operator.
Putting Lineage to Work
In this article, we’ve explored three ways that Airflow can emit data lineage information to a data observability backend: 1) using the already supported operators, 2) developing your own custom extractor, and 3) using inlets and outlets arguments in an operator.
As the Astro-based examples in this article show, this is just a starting point: lineage metadata is most valuable when you put it to use. One common application is to use this metadata to generate a lineage graph: i.e., a visual representation of how a dataset is produced — where it came from, what was done to it, as well as what other datasets (if any) it was combined with — that traces its journey from upstream sources to downstream targets. This graph is useful as a starting point for general-purpose troubleshooting, and lineage metadata can be put to other uses, too, like impact analysis and root-cause analysis (RCA).
All three of the methods described above rely on capabilities that are built into open-source Airflow, meaning anyone can use them to extract lineage from their Airflow tasks. Because OpenLineage isn’t tied to Astro, anyone can make use of lineage metadata, too.
That said, if you don’t use Astro — or a commercial data lineage or metadata management software offering that supports OpenLineage — you’re going to have to set up your own observability backend. At minimum, this entails installing Marquez, configuring your OpenLineage extractors and/or Airflow operators to persist lineage events to it, and, optionally, designing different kinds of analytic views. Thankfully, there are plenty of resources you can use to get started. Bear in mind, too, that because Kaboola, Manta, and other commercial data lineage and metadata management vendors now support OpenLineage, their products can automatically collect, aggregate, and analyze the events emitted by OpenLineage extractors and Airflow operators.
On the other hand, a fully managed service like Astro automates all of this for you, extracting lineage metadata, collecting it in a pre-built observability backend, and generating a lineage graph. Astro also offers a selection of pre-built analytic views, and exposes REST and GraphQL APIs for query access.
DAG authors and ops personnel can use the Astro UI to explore a dataset’s Lineage Graph, drilling into the underlying data to view granular information about upstream and downstream datasets (schema, APIs used for access, etc.), as well as the different types of joins, calculations, or other transformations performed on them. And Astro incorporates other features — like pipeline diff-ing capabilities, which let you see what changed in a pipeline over time — that simplify troubleshooting and diagnosis, and which are also essential for RCA and other diagnostic methods.
We’re always looking for ways to make the experience of using Airflow operators better for our users. If you have a set of workflows that you’d like to get lineage data on, or you feel like there’s room for improvement on the OpenLineage spec, please reach out to us.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.