Comprehensive Guide to Data Pipeline Testing with Airflow
10 min read |
Testing Airflow DAGs is crucial to ensure error-free, reliable, and performant data pipelines. To achieve this, understanding why tests are needed, where they fit in the data pipeline, and where to implement them in your data pipelines is essential. Let’s explore these questions in the context of a data pipeline and then proceed with an example implementation.
This blog post aims to present real-world scenarios and introduce different types of tests that can be used in your data pipeline. Based on your use case, you might choose to implement either all types of tests or only a selected few.
Why include tests in a data pipeline
Consider a data pipeline that reads the data from an S3 bucket, loads it into a Redshift stage table and then upsert the data to the final target table. Assume that this DAG runs on a daily schedule.
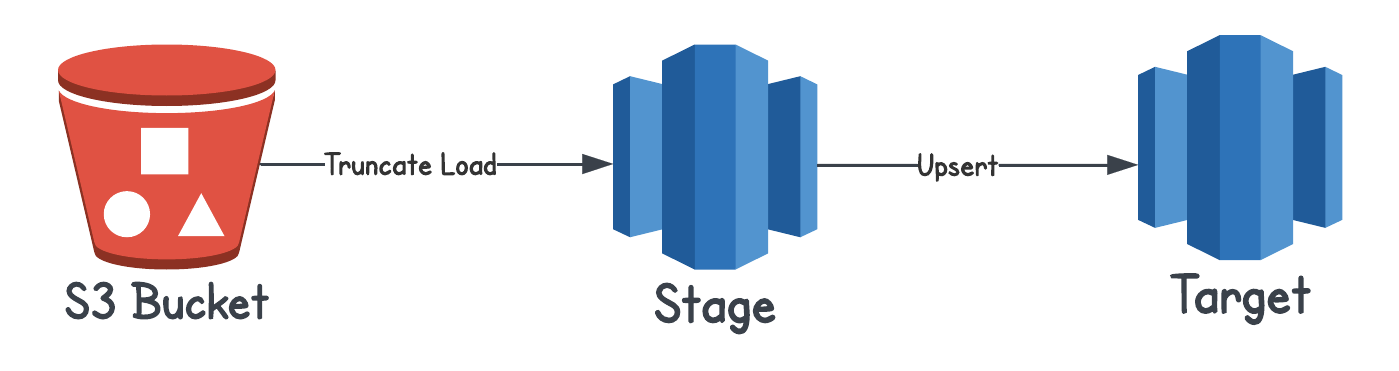
Now, try to think of what all could go wrong with this pipeline:
- DAG issues
- You applied a quick fix to your code to clean the data using
pandasbut forgot to add theimportstatement before deploying or have top-level code that is trying to read a non-existent environment variable. Now, the DAG is throwing import errors and not getting rendered on the Airflow UI. What other DAG parse errors can you think of and how to catch these before deploying? - Assume that this is a reusable data pipeline for loading multiple tables, and before we stage the data, we do some pre-processing. For example, check for a column called
updated_at, calculate its max value and insert it into a metadata table. If a file is missing this column, or it has a junk value or there is a column shift, either the max function or insert into table query will fail. Can we test if these checks are implemented properly usingpytestorunittestin Python and make this pipeline easily adaptable?
- Data issues
- The DAG runs as per schedule, but an empty file arrives from source, and hence no records are loaded in the target but DAGRun is marked as success. Imagine if the target table was used in an
inner join, or is a truncated load - you will lose all the data! How will the business teams be impacted who rely on this data for important decisions? Can Data Quality checks be of any help here?
- Integration issues
- You migrate your DAG from your development environment to a higher environment. The DAG runs successfully but the data seems off and the target table counts are different. Did the DAG process development data in production? Did you use the correct connection based on the environment?
- Someone rotates the security keys and your DAG can’t communicate with Redshift anymore. Can we test the connections before we deploy?
To allow our data pipelines to adapt and scale with our data ecosystem, our code should adhere to standards for input, output, and processing. Adding appropriate unit tests to your code will help you alleviate not only basic programming errors but also the business errors they might cause downstream. In my experience, this is the area where many data engineering teams falter; in trying to be agile and meet deadlines, the focus is on delivery, not on testing. Hence, at times, they incur more tech debt by not writing appropriate unit tests or data quality tests.
Basic tests for a data pipeline
The scenarios we discussed in the previous section can be handled gracefully by incorporating the following tests:
- Tests to check for DAG-related errors, code functionality, and system integration errors:
- DAG Parse Tests to detect import errors: Parse the DAGs in your local development environment or within your CI/CD pipeline before they are deployed to your Airflow. These tests help to identify basic syntax errors and import errors.The Astronomer Astro CLI provides these by default, and they can be explicitly executed using
astro dev parseor implicitly usingastro deploy. This command uses the default tests defined in your Astro project’s.astro/test_dag_integrity_default.pyfile. These tests are not part of your DAGs but are executed before you deploy the DAGs to your environment. - Unit tests to check code functionality or to identify integration issues: ** ** Unit tests are focused and isolated tests to test a specific functionality of the code. They help ensure that each part of the codebase works correctly in isolation, which contributes to overall code reliability and maintainability.
pytestis a testing framework that makes writing and executing unit tests easier and more efficient. Astro CLI by default supports tests usingpytest.
- Data validation tests to check for data issues: These are the types of checks that can be added to your DAGs to perform validation on the data being processed and raise an error before it impacts downstream processes. They help in the long run by saving unnecessary processing time and and preventing the accidental overwriting of any useful/existing data.For example, in our data pipeline, once we have confirmed the file has arrived using a
FileSensor, we can add tests to verify if the file is non-empty by checking if its size is greater than 0 bytes, or if the file has header, then checking for the number of records to be greater than 1. You could also load your data into a stage table and run checks like verifying if there are dates that do not match the required format or if a column is not null to avoid errors further down in the pipeline. - Data quality tests to assess the quality of the data: These tests evaluate the data for reliability, accuracy, completeness, timeliness, and consistency. They ensure that the data used for business decisions or analytics is of high quality. For example, this might involve checking the amount column against a threshold, verifying whether a country code is valid according to business rules, or checking for any duplicate keys in the target table, among others. The following SQL queries provide examples of a count check and a recency check:
-- Data count check
SELECT
CASE
WHEN COUNT(*) >= <threshold> THEN 'Pass'
ELSE 'Fail: Data count below threshold'
END AS data_count_check
FROM
your_table;
-- Recent data check
SELECT
CASE
WHEN MAX(updated_at) >= CURRENT_DATE - INTERVAL '<days>' DAY THEN 'Pass'
ELSE 'Fail: Data not recent'
END AS recent_data_check
FROM
your_table;The tests we discuss here are in no way an exhaustive list of different types of tests, but some of the commonly used ones. As a team moves forward in their data journey, the complexity of these tests will increase along with number of different types of tests.
Where should I include tests in a data pipeline
- DAG parse tests: The easiest way to include DAG parse tests is using The Astronomer Astro CLI. The basic tests to check your DAGs for import errors are already included in your Airflow project initialized with Astro CLI. This allows advanced users to customize add new in
.astro/test_dag_integrity_default.py. For example, you could add a monkey patch to handle a top-level code in your DAG. Learn how they work usingastro dev parsein the Astronomer Docs. - Unit tests: In an Airflow project initialized with Astro CLI, you can include unit tests in the
testsdirectory. Some example tests are already included to get you started; for instance, check if the DAGs havetagsor if the tasks have sufficient retries. This test file exists intests/test_dag_integrity.py. You can include more test in this folder per use case, and they can be executed usingastro dev pytestcommand. For example, the following test checks the method that verifies the existence of theupdated_atcolumn:
import pandas as pd
import pytest
def check_updated_at_column(file_path):
# Read the file into a pandas DataFrame
try:
df = pd.read_csv(file_path)
except FileNotFoundError:
return False, "File not found"
# Check if 'updated_at' column exists
if 'updated_at' in df.columns:
return True, "Column 'updated_at' exists"
else:
return False, "Column 'updated_at' does not exist"
@pytest.mark.parametrize("file_path", ["path/to/your/file.csv", "path/to/another/file.csv"])
def test_check_updated_at_column(file_path):
assert check_updated_at_column(file_path)[0], check_updated_at_column(file_path)[1]For a robust development experience, include astro dev pytest as part of your CI/CD pipelines. This ensures seamless and smooth code promotion between different Airflow environments.
- Data validation and data quality tests: These tests can either be part of your DAG file, or you can import them into your DAG file. Typically, these tests are defined as reusable code in a Python package that can be shared across the organization. They are more focused on the data and not Airflow functionality or Airflow objects.You can use Airflow Operators directly to create your own testing framework using SQL Check operators. Airflow also seamlessly integrates with existing testing frameworks like Soda or Great Expectations. You can create your own custom, reusable operators using these frameworks that can be shared across teams.A combination of Data Quality checks with Airflow Notifiers enables you to alert your stakeholders in advance and allows you to fix these errors before the production system is impacted. You can use
BranchPythonOperatororShortCircuitOperatorto branch or end your processing based on conditional logic. In Astro, you can make this more robust by using Astro Alerts, which require no change to your DAG code!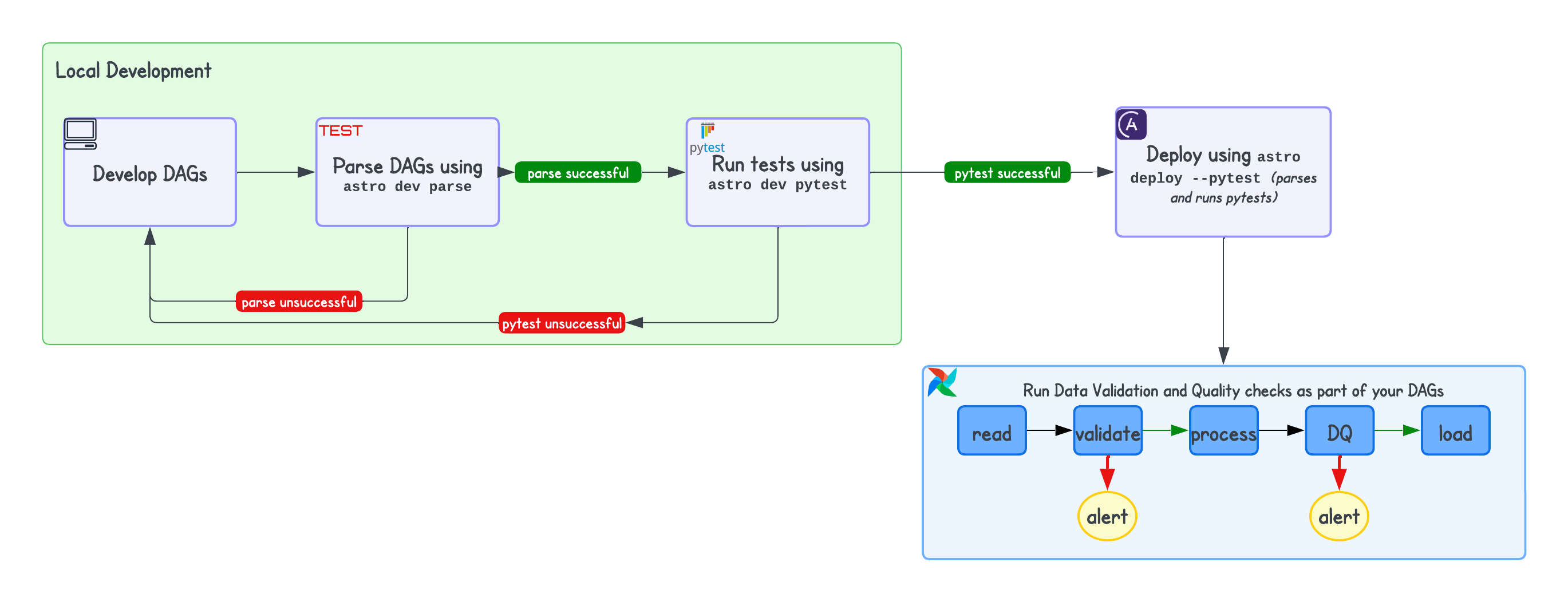
Enforce checks using Airflow Policies
In some cases, Airflow administrators want to implement controls to ensure that DAGs meet certain standards across the organization or teams. They prefer to centralize these controls for quality assurance. Airflow Cluster Policies can be used for this purpose. These policies are not tests but checks that allows you to enforce quality standards. This approach enables users to avoid duplicating certain basic tests or checks for each Airflow project separately. Additionally, for administrators, it provides a central location to manage and enforce these standards.
Cluster policies are a set of functions that Airflow administrators can define in their airflow_local_settings module or using the pluggy interface to mutate or perform custom logic on a few important Airflow objects like DAG, Task, Task Instance etc. For example, you could:
- Enforce a default user for all the DAGs or based on some condition
- Enforce certain tags for DAGs, which can be default or based on a condition
- Enforce development DAGs do not run in production, based on an environment variable
- Enforce a task timeout policy
Watch this deep-dive video into cluster policies by Philippe Gagnon.
Conclusion
The tests we discussed here are just a subset of a larger set that we can implement to make more robust and stable pipelines. However, this subset is good enough to get started with if you are new to testing in Airflow or any other data pipelines. Beyond this, there are advanced tests that you can implement, like performance tests, optimization tests, scalability tests, end-to-end system tests, security tests, and so on. We can dive deeper into these as well in future blogs.
In conclusion, data validation tests, unit tests, and data quality checks play vital roles in ensuring the reliability, accuracy, and integrity of data pipelines and hence, your data that powers your business. These checks ensure that while you quickly build data pipelines to meet your deadlines, they are actively catching errors, improving development times, and reducing unforeseen errors in the background. Astro CLI plays an important part in this by providing commands like astro dev parse and astro dev pytest to integrate tests seamlessly. Additionally, it also gives you the option to test your Airflow project when upgrading to a higher version for Python dependencies and DAGs against the new version of Airflow.
Start optimizing your Airflow projects today with Astro CLI—your gateway to robust, error-free data pipelines. Also, check out the detailed documentation on testing Airflow DAGs in the Astronomer docs.

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.