Astro Observe is Now Generally Available


Companies are building their competitive advantage on data – AI models that drive customer interactions, automated financial reporting that powers decision-making, or personalized recommendations that increase revenue. But all of it depends on data pipelines that actually work—delivering fresh, accurate, and reliable data when it’s needed most.
And yet, too many teams continue to operate reactively. When a pipeline fails, someone gets an alert, scrambles to debug, and spends hours, sometimes days, tracking down the issue. If a data product misses its SLA, the impact ripples across teams – machine learning models make flawed predictions, dashboards show stale numbers, and compliance reports get delayed. By the time anyone realizes the true impact, it’s too late.
Today, data products are as mission-critical as software applications. If an application goes down, engineers have tools to detect, diagnose, and resolve the issue – often before users even notice. But for too long, data teams have lacked the same level of operational rigor. This is why we’re excited to share that Astro Observe is now generally available. With observability and orchestration in a single platform, data teams no longer have to operate in the dark. Instead of waiting for failures to happen, they can see risks coming, diagnose issues faster, and ensure that data products perform as expected every time.
A Unified Approach to Orchestration and Observability
Apache Airflow has become the standard for orchestrating complex data pipelines, but orchestration alone doesn’t guarantee that those pipelines are running reliably, efficiently, or cost-effectively. Data teams need a full picture of what’s working, what’s at risk, and what needs to be optimized. That’s where Astro Observe comes in.
By combining deep observability with Airflow orchestration, Astro Observe gives teams real-time visibility into pipeline health, predictive insights to prevent failures, and automated diagnostics to resolve issues faster. Astro Observe is essentially the single pane of glass into data product health and performance for modern data teams.
Organizations across industries – from financial services to retail to AI-driven enterprises – have used Astro Observe throughout the private and public previews to set SLAs for their data products, map dependencies across pipelines, receive AI-driven recommendations for optimization, and get alerted before problems impact the business.
Now, with General Availability, we’re adding even more powerful capabilities to help teams move beyond reactive troubleshooting into proactive, strategic data operations.
New in GA: A Smarter Way to Manage Data Pipelines
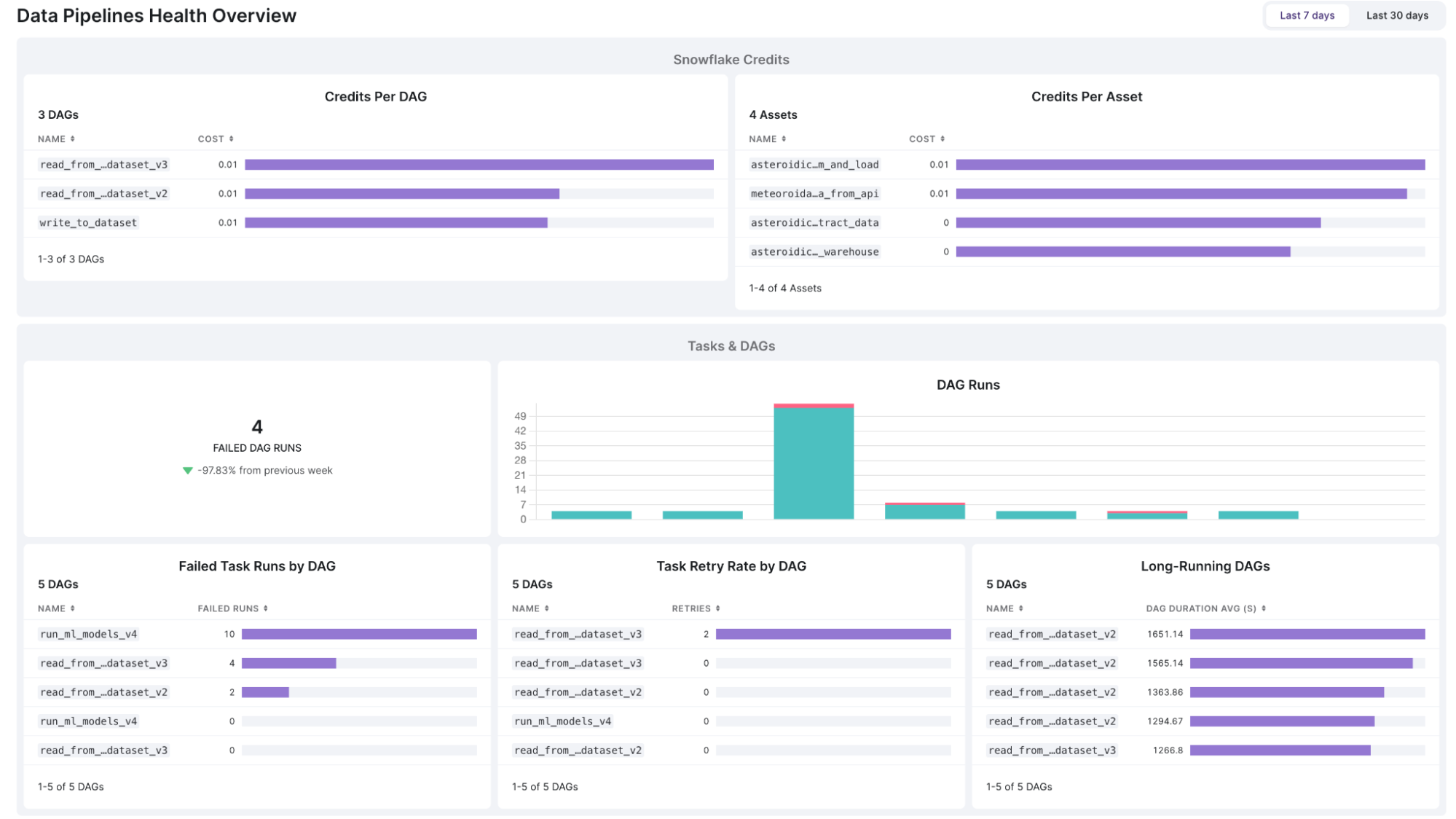
Data Health Dashboard – A Real-Time Control Center for Data Teams
Every day, data teams are responsible for keeping several, sometimes several thousand, pipelines running. But too often, they don’t know something is wrong until a stakeholder reports stale data or a model’s predictions suddenly go haywire. The challenge isn’t just fixing problems – it’s knowing where to look in the first place.
The Data Health Dashboard gives teams a single, real-time view of their pipeline ecosystem, showing which workflows are healthy, which need attention, and where resources are being consumed inefficiently. Instead of spending hours piecing together fragmented metrics from different tools, teams can immediately see the most critical performance insights – DAG runtimes, task failures, pipeline bottlenecks, and cost spikes – all in one place.
Optimizing Snowflake Cost Management - Spot Trends and Stop Waste
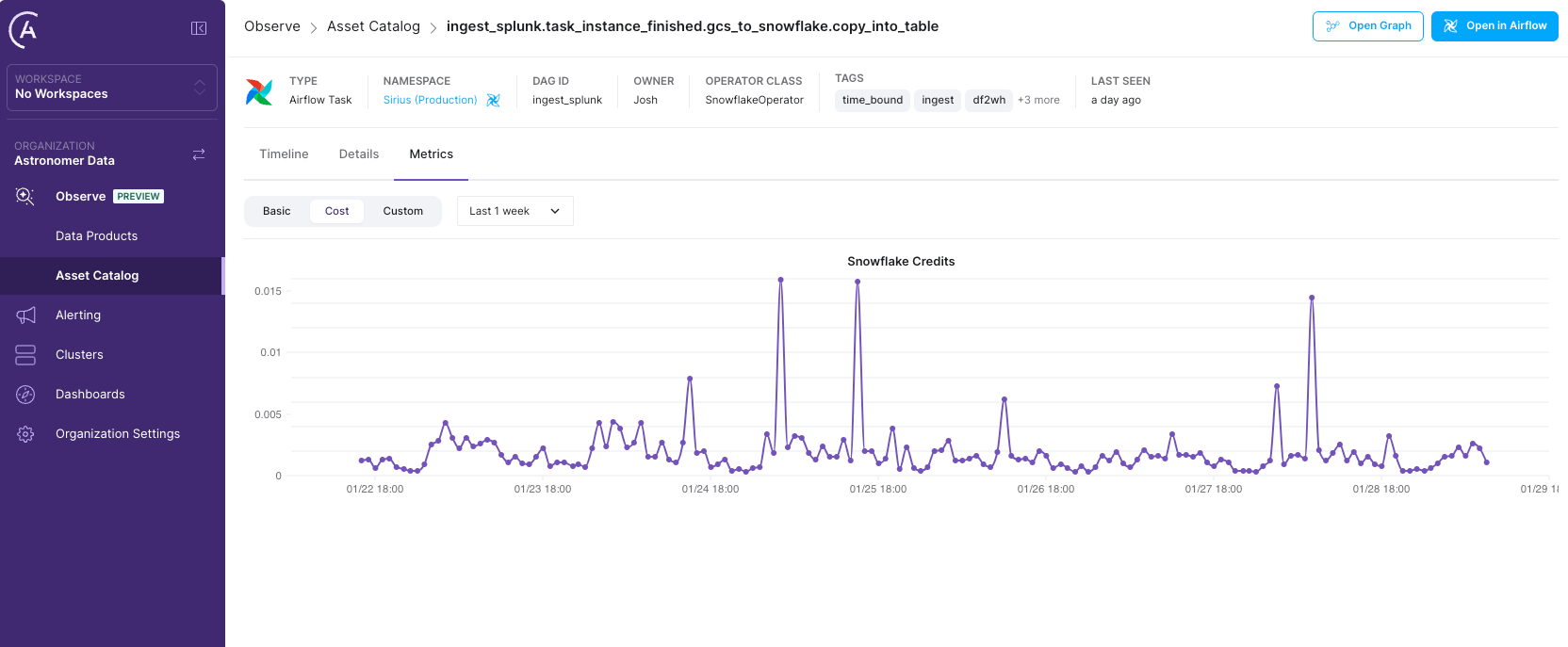
Managing Snowflake costs effectively requires visibility into how data pipelines impact compute spend. While Snowflake provides cost reporting, teams often struggle to correlate credit consumption with specific workflows, making it difficult to identify inefficiencies and control expenses.
Astro Observe solves this by offering task-level analysis of Snowflake credit usage alongside pipeline activity. Teams can quickly detect cost anomalies, pinpoint inefficiencies, and optimize orchestration to eliminate waste. By visualizing trends and identifying problem areas, they can proactively manage spend and improve efficiency.
With Astro Observe, data teams gain the insights needed to optimize Snowflake workloads, reducing unnecessary costs while maximizing performance.
AI Log Summaries – Diagnose Issues in Seconds, Not Hours
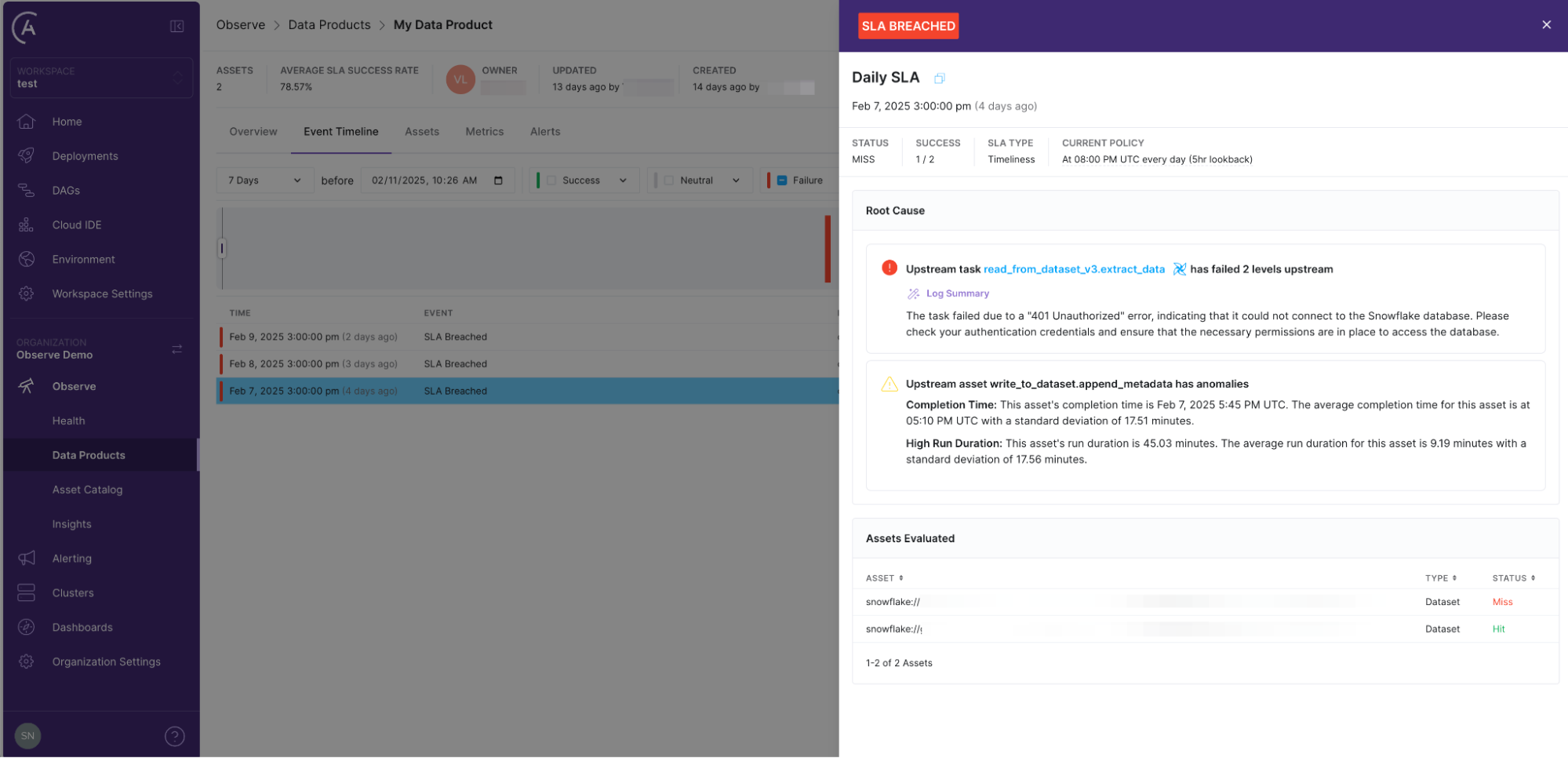
When a pipeline fails, the clock starts ticking. The faster an engineer can diagnose the issue, the faster they can fix it. Debugging a failure by digging through thousands of log lines is not only time-consuming but also error prone.
Astro Observe changes that. Observe streamlines root cause analysis by immediately identifying upstream failures and anomalies that impacted your pipeline and caused missed SLAs. Once teams have pinpointed the issue, like a failed task, AI Log Summaries provide an instant, human-readable explanation of what went wrong, where to look in order to fix it, and how to prevent it from happening again. By eliminating the guesswork, incident resolution times drop from hours to minutes.
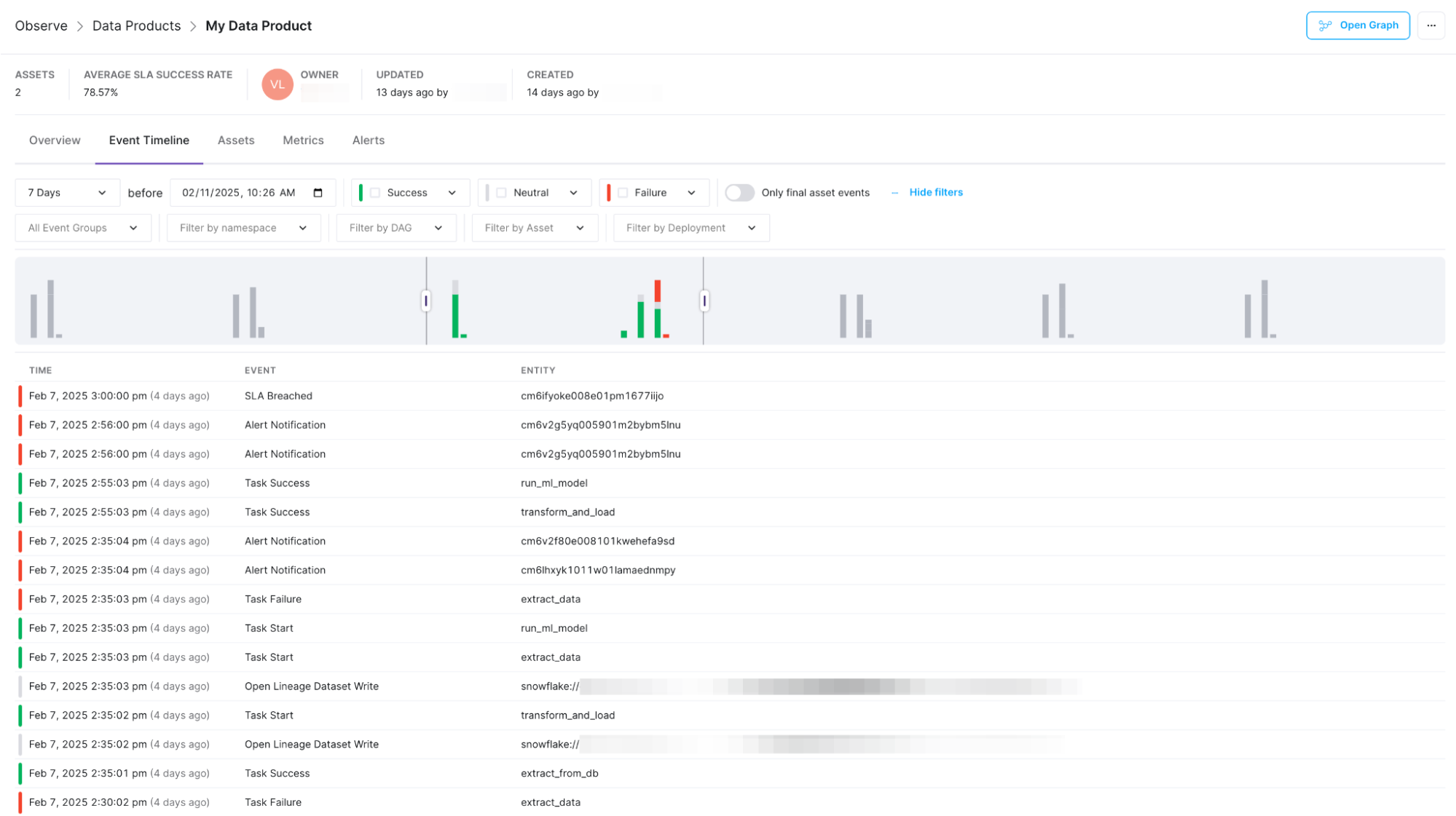
Timeline View – Connecting the Dots Between Pipeline Failures
Not all failures are random. Some happen because of long-term patterns — unless a team is actively looking for these trends, they’re easy to miss.The Timeline View solves this by giving teams a historical perspective on pipeline health. Instead of treating failures as isolated incidents, teams can now see patterns across time, identify recurring issues, and understand which failures are part of a larger trend. For example, did issues arise as part of a slow degradation over time, or from a seasonal traffic spike, or an unnoticed dependency that started failing weeks ago.
With visualizations that link failures to logs, SLAs, and past incidents, data engineers can quickly answer critical questions that were once difficult to pinpoint:
• Is this a one-off failure, or part of a bigger problem?
• Did a recent infrastructure change impact pipeline stability?
• Is this SLA consistently being missed, or is it an anomaly?
By connecting past failures with future risks, teams can move beyond constant fire fighting and reactive troubleshooting into proactive data reliability management.
The New Standard for DataOps
Today, data products are as mission-critical as software applications. If an application goes down, engineers have tools to detect, diagnose, and resolve the issue – often before users even notice. For too long, data engineering teams have lacked the tools and operational rigor of their software engineering peers. Astro Observe changes that.
With observability built directly into orchestration, teams can now:
• Ensure data products meet SLAs—every time
• Proactively catch failures before they impact the business
• Diagnose and resolve issues in minutes, not hours
• Optimize pipeline performance and cost-efficiency
Data reliability is no longer optional. It’s the new standard.
Ready to See Astro Observe in Action?
With Astro Observe, data teams no longer have to guess what’s happening in their pipelines. They can see it, understand it, and optimize it before failures happen.
If your organization is ready to eliminate reactive troubleshooting and take control of data pipeline performance, explore Astro Observe today.
Learn more about Astro Observe by joining our upcoming Intro to Astro Observe webinar on February 20, or book a demo.
