Why Enterprise AI Struggles: The Context Gap, Data Gravity, and What Comes Next

More data, less understanding
For years, the dominant narrative in enterprise data strategy has been clear: more data equals more value. Centralize your data, warehouse it, and unlock insights. But now, as AI systems take center stage, that playbook is showing cracks.
The problem? We’ve mistaken data for knowledge.
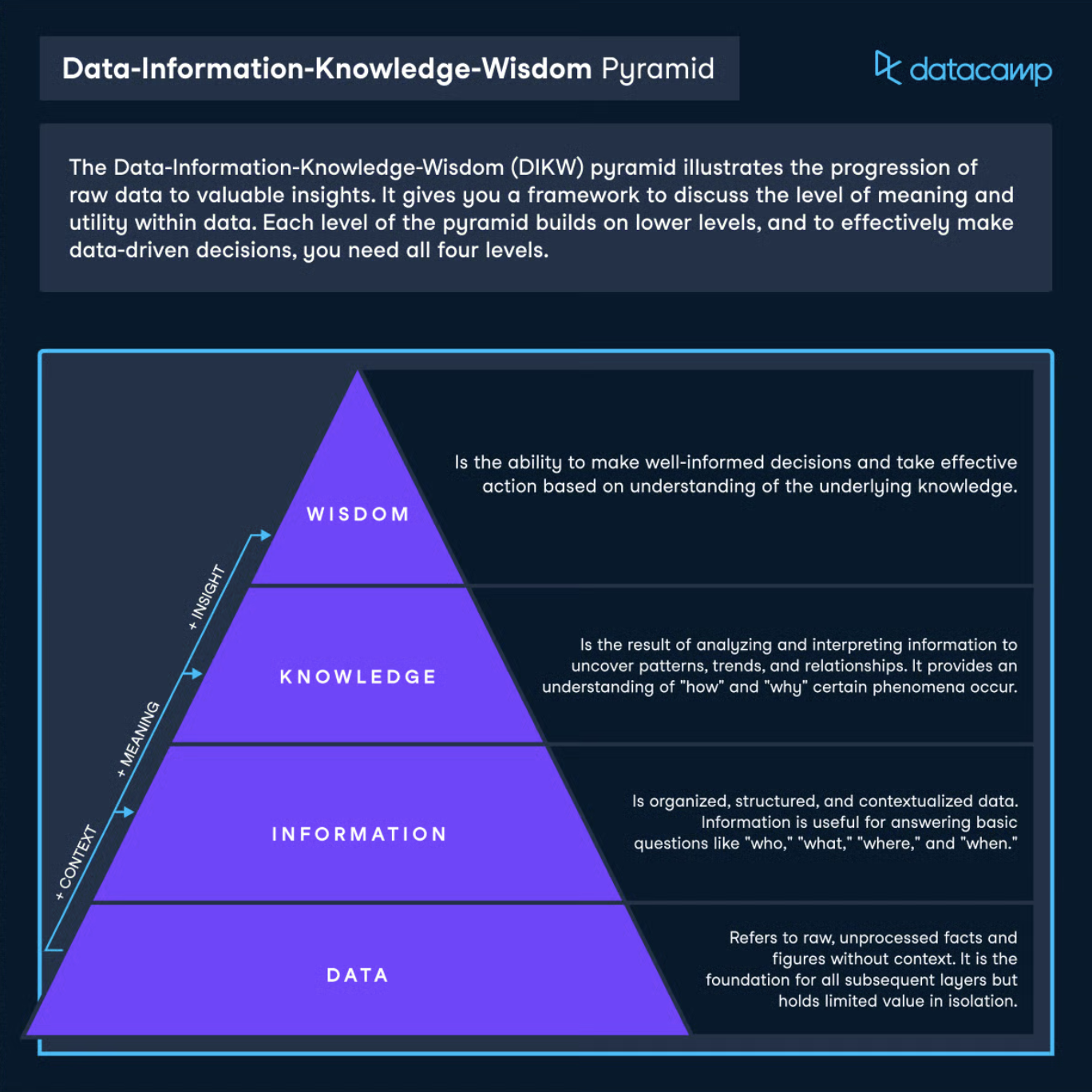
Source: Datacamp
The data-information-knowledge-wisdom hierarchy is a foundational concept in information systems that seems more relevant than ever. In short, it describes how raw data is organized into information by adding context, then interpreted and synthesized into knowledge, thereby enabling understanding and decision-making. In a world where large language models are being thrown at everything from analytics to supply chain management, that leap from data and information to knowledge—the part where applied context and meaning lives—has become the bottleneck. These systems are powerful, but they lack grounding. They don't know the difference between two nearly identical columns. They can't tell whether a metric is actually trusted by the business or something someone spun up in a hurry two quarters ago and forgot to clean up.
The context gap
Imagine joining a team that's worked together for years. They speak in shorthand. They finish each other's sentences. There's a sort of creative joy in that kind of shared context. Now imagine dropping into that team as a new hire. You're smart, you're experienced, but you're missing years of backstory. Everything looks familiar but slightly off. That's what it's like for AI inside most systems today but it’s even more pronounced inside sophisticated data platforms where context is everything. This is the context gap, and it's the real reason so many AI initiatives look great in demos and flop in production.
Here’s what the context gap looks like in practice:
- The misleading sales spike: A model recommends a product because it appears to be selling well, but this "spike" was actually just a data correction when someone fixed reporting numbers from last quarter. If the AI knew about this manual fix, it wouldn't mistake this artificial bump for genuine customer demand.
- The outdated database query: An AI writes what looks like perfect code to pull data from a table that nobody uses anymore. The company moved to better data sources months ago, but the AI doesn't know this. With proper context, it would direct you to the current tables instead of the abandoned ones.
- The false revenue alarm: Your dashboard sends an urgent alert about dropping revenue that gets everyone worried. But this drop was actually planned as you’ve changed your pricing strategy last month. If your systems knew about this business decision, the alert would either explain "this is expected due to our new pricing" or not trigger an alarm at all.
- The misguided customer outreach: An AI suggests winning back "inactive" customers who haven't used your product lately. What it doesn't know is these customers left because they had bad experiences that were documented in your support system. With this context, the AI would recommend fixing your service issues first, rather than awkwardly reaching out to unhappy former customers.
These are not edge cases. They’re the inevitable result of systems working with data that looks clean but lacks memory, provenance, and meaning.
The architecture issue
Part of the issue is architectural. The last decade has been defined by what we might call the data gravity era—move everything into one place, typically a warehouse or lakehouse, and build your stack around that center of mass. It worked. It still works, in many cases, if you’re optimizing for the latency of information retrieval. But there are tradeoffs we haven't talked about enough.
Centralized systems are incredibly good at one thing: giving you a single place to ask questions. But they don't preserve nuance. They strip away history. They break easily when upstream changes happen. And for all the effort we've put into things like medallion architectures and data contracts, the truth is that many of us are still debugging why a dashboard broke because someone renamed a column upstream.
What gets lost in these architectures is not data—it's understanding. You can write the best data pipeline/DAG in the world, and still lose the thread of why a transformation exists in the first place. Who asked for it? What it was supposed to support. Whether the underlying assumptions are still true. That kind of knowledge is often tribal, or locked in Slack threads, or just gone.
Where we go from here
So now we’re at a fork in the road.
On one side, we can keep going down the centralization path. There are good reasons to do that—performance, consistency, governance. You want your executive dashboards running on something predictable, and you want your analysts working off of the same definitions. But that model comes with costs: infrastructure, organizational complexity, a constant need to reconcile pipelines that don't quite agree, not to mention lengthy upfront design and ongoing maintenance to meet new business requests.
On the other side, we’re seeing more systems being built to support an alternative approach: instead of centralizing everything, teams are experimenting with keeping data where it already lives (in the systems where it has meaning) and finding ways to query it directly, in context. The Model Context Protocol is one early example of this. Agent-based systems are another. It’s messy, early, and incredibly promising. Because in those environments, AI systems can start to behave less like disoriented new hires and more like longstanding teammates.
The reality is that both models will coexist. Centralized warehouses aren't going away. But neither is the need for context-rich, flexible, decentralized access patterns. And the thing that ties it all together—the glue, if you will—is data orchestration.
Apache Airflow®, and by extension Astro, is evolving to meet this new reality. It's not just about running scheduled jobs anymore. It's about coordinating work across systems, managing both traditional ETL and on-demand or event-driven AI-driven workflows, and enforcing the kind of observability and lineage that lets you sleep at night.
For years, we’ve moved compute to where the data lives, piling it into centralized warehouses and lakehouses so we could query it fast and at scale. But AI shifts the equation. The value isn’t just in the data itself, but in the context that surrounds it: who created it, what it means, how it’s been used, and why. And that context often lives outside the warehouse: in SaaS systems, APIs, and operational tools.
So maybe it’s time to flip the model and bring compute and inference to where the context already lives.
Either way, if you’re serious about getting your AI apps to production — at scale, with trust, and with full context — you need a rock-solid data orchestration foundation.
