Ask Astro: Operationalizing Data Ingest for Retrieval Augmented Generation with LLMs, Part 3
12 min read |
Business leaders across industries are exploring potential use cases for leveraging large language models (LLMs). As these teams move towards production, it’s not always clear how best to establish operational processes.
In part 1 of this series, we discussed some of the challenges with operationalizing LLM-powered applications. In part 2, we introduced Ask Astro as a reference implementation of Andreessen Horowitz’s Emerging Architectures for LLM Applications. Here, we dig deeper into the reference implementation with a discussion of operationalizing the ingestion and embedding of data to power Retrieval Augmented Generation with LLMs.
The Origins of Ask Astro: Exploring Retrieval Augmented Generation
The story of Ask Astro unsurprisingly starts where many others have. An internal inventor created a prototype, drawing upon years of subject-matter expertise to solve a specific problem. Namely, how do we capitalize on the wealth of knowledge contained in a vast array of documentation sources that are the natural byproduct of one of history’s largest and most active open-source communities?
Astronomer leadership quickly realized not only the staggering power of the LLM and usefulness of the application but also started asking questions about how we keep it relevant, accurate, and efficient over time.
Unsurprisingly, the ability to ingest, embed, update, search, and retrieve unstructured data is at the core of building RAG applications
As a Retrieval Augmented Generation (RAG)-based application, the performance – here we mean the ability of the application to generate the desired response – is a function of the quality of retrieved data, the ingenuity of the prompt chaining, and the power of the LLM itself. For now, we will assume that the audience is not building or fine-tuning LLMs and that, beyond selecting an LLM, the power of the model itself is more or less out of their hands. Subsequent blogs in this series will focus on the prompting and techniques like hybrid search and reranking. For this blog, it’s all about the data. Unsurprisingly, the ability to ingest, embed, update, search, and retrieve unstructured data is at the core of building RAG applications.
Keep it Modular: Building the Foundation for Ask Astro
Ask Astro started as a combination of LangChain as well as an in-memory vector store using FAISS, and a Slackbot frontend. The simplicity of LangChain is one of its super powers, as it consolidates both index-time operations (ie. document preparation, loading, and indexing) with query-time actions (chaining, search, prompting, etc.). In order to operationalize this, however, the first step was to separate the backend indexing operations from the frontend query operations.
As pointed out in part one of this series, the backend processes for extracting, ingesting, embedding, etc look very similar to existing data engineering practices for extract, load, and transform (ELT). Following are some of the differences with LLMs and how they were addressed with Ask Astro.
Select a Vector Store for Scalability and Reliability
While in-memory indexes are often used in the development of prototypes, the importance of the vector store for the scalability and reliability of the application as a whole warrants the use of a vector database. Selecting the vector database should follow the same philosophy as the rest of the IT process (ie. cloud vs on-premise, hosted vs. BYO, open source vs proprietary, etc.).
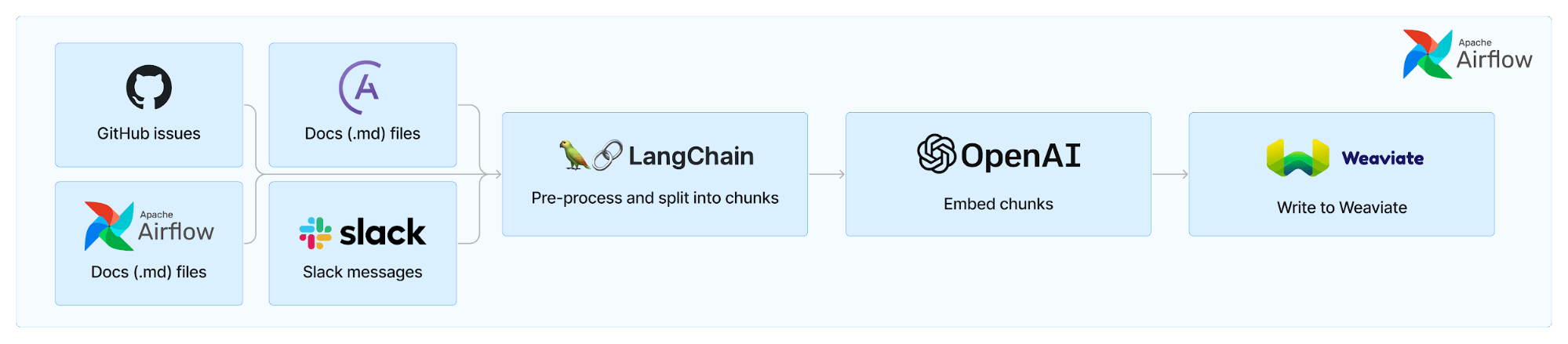
For the first iteration of Ask Astro we selected Weaviate because of its “open-core plus hosted” structure. This is aligned with Astronomer’s model and also fits with how many teams use Airflow. Additionally, Weaviate’s scalability and speed were important for user experience and latency. As detailed below in the devops section, Weaviate integrates well with the Astro CLI and Astro hosted deployments. We created a Weaviate provider for Airflow which simplifies management while enabling clean, readable, and maintainable Directed Acyclic Graphs (DAGs). A version of this provider is planned to be added to Airflow.
Additional providers for Pinecone and pgvector will be added, and the reference implementation will be extended to select between these vector databases. Because this is a community resource, we would love to see many other implementations. Submit comments or pull requests with providers you would like to see as part of this.
Optimize Schema Design for Vector Databases
The schema specifies how documents are represented in the vector database. This is use-case dependent and the one thing to expect is the need to try many variants. Setting up the code to allow for experimentation (see below on bulk vs. nightly ingest) will provide the flexibility needed to try and retry different schemas.
Ask Astro’s schema started with a small number of sources represented by a couple of document classes with metadata-specific properties. As more sources were added through development, the decision was made to simplify the schema to a single document class (‘Docs’) with very generic metadata. This allowed quicker development without constantly changing and updating the schema but came with a tradeoff of refined search results. An effort is underway to expand the schema with indexed, vectorized fields to support hybrid search.
A simple schema with vector search can still provide great results. It's better to start with a simple schema and iterate quickly than to spend months planning a complex schema that will likely change many times during the development of the project. Starting with a simple schema allowed us to iterate quickly – as the scope of Ask Astro grows, we do expect the schema to change over time.
Simplified schema
{"classes": [
{
"class": "Docs",
"properties": [
{"name": "docSource"},
{"name": "docLink"},
{"name": "content"},
{"name": "sha"}
]}]
}Select a Model for Ingestion
There are numerous open source, public, use-case-specific, or proprietary LLMs on the market. with more arriving every day. When it comes to ingest, the primary concern is around selecting an embedding model. During early development, when the quality of embeddings is less important than building structures and processes, Airflow DAGs can be easily adjusted to use a downloaded, local model such as HuggingFace’s Sentence Transformers. If using APIs, remember that a lower price option allows for experimentation and re-embedding with different chunking strategies.
Model definition in schema
"moduleConfig": {
"text2vec-openai": {
"model": "ada",
"modelVersion": "002",
"type": "text",
"vectorizeClassName": "False"
},
"reranker-cohere": {
"model": "rerank-multilingual-v2.0"
},
"generative-openai": {
"model": "gpt-4"
},
"qna-openai": {
"model": "text-davinci-003",
"maxTokens": 100,
"temperature": 0.0,
"topP": 1,
"frequencyPenalty": 0.0,
"presencePenalty": 0.0
}
},Ask Astro was originally built with OpenAI Embeddings which has excellent conceptual extraction at a very low price. The primary issues encountered were with API rate limits, which can be easily addressed by task retries in Airflow. The Weaviate provider submits batches of data for vectorization and includes upsert logic as well. If an ingest task fails due to rate limits, the retry will skip previously ingested chunks and continue. Setting a retry_delay appropriately helps avoid hitting rate limits.
Additional considerations for model selection relates to privacy and cloud contracts. Ask Astro’s document sources are all publicly available, and as such, the OpenAI Embeddings model is acceptable for ingestion. For embedding questions at query time, it is necessary to account for potential privacy and data use policies, and the Ask Astro frontend uses Microsoft Azure OpenAI endpoints.
Select an Effective Chunking Strategy for Documents
Large documents will need to be split into chunks to fit within the context window of the selected model. This is perhaps the most important consideration for retrieval performance and, like schema design, is very use-case dependent. Also similar to schema design, you can expect to try many options, and the best approach is to start with something simple and set up the development environment that encourages quick iterations and experimentation.
The Airflow Taskflow API, along with tools such as LangChain, Haystack, and LlamaIndex, make it very easy to use best-of-breed logic for splitting documents. In fact, Airflow DAGs can be configured to use multiple modules (along with multiple chunk size and overlap parameters) in parallel in order to optimize RAG performance. In this way, Airflow can perform operations similar to a parameter grid search optimization used in machine learning operations.
markdown_tasks = [md_docs, rst_docs]
chunk_sizes = [1000, 2000]
split_md_docs = task(split.split_markdown)\
.expand(dfs=markdown_tasks,
chunk_size=chunk_sizes)Ask Astro started with a recursive character text splitter from LangChain. The markdown header splitter was also tested but initial results showed poorer retrieval performance. Additional work is underway to create an evaluation pipeline which will use Arize Phoenix along with parallel Airflow DAGs and tasks to identify an optimal chunking strategy.
Set Up for Experimentation
As mentioned multiple times above, the need for experimentation is key. This is a rapidly developing field, and even workflows that have been in place for months may benefit from new databases, services, models, or techniques. Creating infrastructures and workflows that simplify and encourage experimentation is key not only for quick development but also for long-term maintenance.
- Infrastructure: The Weaviate vector database was selected initially for Ask Astro, in part, because of its local development options. The Astro CLI is the easiest and fastest way to have Airflow up and running in just a few minutes.
Code sample
% brew install astro
% git clone https://github.com/astronomer/ask-astro
% cd ask-astro
% export ASK_ASTRO_ENV=’local’
% astro dev startThe Astro CLI uses Docker Compose and can run seamlessly with other services for local development. Adding Weaviate is as simple as creating a docker-compose.override.yml file and providing connection information in Airflow Connections or as an environment variable. This allows for rapid experimentation locally without incurring additional costs for cloud infrastructure.
- Development Workflows: In addition to local infrastructure for testing, the concepts of Airflow DAGs natively support experimentation. Ask Astro was designed with two types of DAGs and modular code.
- Modular Components: The logic for extracting source data, splitting/chunking the documents, and ingesting into the vector database exist in the project’s “include” folder. This way, additional sources or different chunking or ingest can be added over time and are version controlled with any CI/CD processes in place.
- Test Load: The ‘ask-astro-load.py’ DAG combines all the sources into one workflow and is used for ingesting a baseline of documents. The specified sources should be a relatively small but statistically relevant subset of the data. If the size of the full corpus is relatively small, there is no need to truncate the documents. Creating this test load workflow enables the following:
- Reduce API calls: The first time the DAG is run, it serializes extracted documents to parquet files. This first run may extensively use APIs to extract data from native sources and may result in rate limit failures. Tasks that use the same API keys can be changed from parallel to serial, and by setting retries and retry_delay, the tasks can complete despite the limits.
@task()
def extract_astro_registry_cell_types():
try:
df = pd.read_parquet("registry_cells.parquet")
except Exception:
df = extract.extract_astro_registry_cell_types()[0]
df.to_parquet("registry_cells.parquet")
return [df]- Rerun DAGs: After the first DAG run, subsequent bulk ingest will read from the local files which allows quick iteration. The DAG uses the WeaviateCreateSchema operator to overwrite existing data so trying a new chunking strategy is as easy as clicking the “play” button.
- Ingest from a baseline: The bulk load DAG is also configured to optionally ingest from a known baseline. This is useful when evaluating changes in the frontend systems while ensuring a stable, known document structure and embeddings.

- Test Workflows: When pipelines are ready for integration testing, the Airflow instance can simply be deployed to a hosted Astro deployment with a new connection string for a hosted Weaviate Cloud Services instance.
Code sample
% astro login
% astro deployment create -n ask-astro-test
% astro deploy -n ask-astro-test
% astro deployment variable update -l
% astro deployment variable create -n ask-astro-test ASK_ASTRO_ENV=testDevOps and Production Workflows
Ask Astro uses CircleCI for pre-commit checks. With Astro CI/CD is a first-class construct and further integration tests will be added for things like promoting from dev to prod. From a manual promotion process, the steps look similar to the above process of deploying from local development to test with hosted instances. In addition to the “test load” DAG, the Ask Astro template also includes separate DAGs for each source system, which are intended to run nightly.
These DAGs use the same logic from the extract, split, and ingest code in the include directory. Separating the nightly ingest DAGs into source-specific workflows allows for more flexibility to deal with source system update windows, API rate limits, etc. Here, task retry is also important for dealing with intermittent external issues.
Enhance Parallelism and Dynamic Updates in Airflow
Dynamically generated tasks are a core component in Apache Airflow® and allow users to specify a list of sources for ingestion of each data type. The ask-astro-load-github DAG, for instance, will iterate over a list of different github repositories to create tasks. Airflow will automatically create parallel workflows based on these dynamic tasks.
Code sample
markdown_docs_sources = [
{'doc_dir': 'learn', 'repo_base': 'astronomer/docs'},
{'doc_dir': 'astro', 'repo_base': 'astronomer/docs'},
{'doc_dir': 'docs', 'repo_base': 'OpenLineage/docs'}
]
md_docs = task(extract.extract_github_markdown, retries=3)\
.partial(github_conn_id=_GITHUB_CONN_ID)\
.expand(source=markdown_docs_sources)
)Sources that use the same extract, split, or ingest logic can be added with a simple update to the list.

In general, the philosophy behind Ask Astro’s ingest process is all about modularity and speed of experimentation. LLMs, like all machine learning and AI, are “living software” that morphs over time. With LLMs, the pace of innovation is very fast at the moment and RAG-based applications need not only high-quality processes and frameworks for automated, audited, and scalable ingest but also flexibility for efficient experimentation. Apache Airflow® augments LLM application development frameworks and models by bringing all the things you need for day-2 operations and simplified development.
What’s Next…
So, you’ve got great processes and infrastructure in place to build production-quality pipelines for your LLM application. You’ve also got great tools to simplify experimentation, but part and parcel with experimentation is the need to evaluate the experiment. How do you know if an experiment yields better or worse results? This too is a workflow perfectly suited for Apache Airflow®.
In the coming series, we will add to this discussion of ingest with additional practices for evaluating the results of ingest and some thoughts on setting up automated experimentation. We will also cover topics like hybrid search, generative feedback loops, reranking, prompt engineering practices, and more.
As you explore Ask Astro and the powerful combination of LLMs and Apache Airflow®, imagine the possibilities for your own projects! With the templates we're making available to the community today, you'll have a head start in creating your own intelligent applications. Getting started with Apache Airflow® is now easier than ever: launch a free trial of Astro and have Airflow up and running in under 5 minutes.
Other articles in this series

Get started free.
OR
By proceeding you agree to our Privacy Policy, our Website Terms and to receive emails from Astronomer.