Airflow in Action: Supercharging Data Science and ML Workflows At Apple

At this year’s Airflow Summit, Neha Singla and Sathish Kumar Thangaraj, senior software engineers on Apple’s Data Platform team, presented the session Streamline data science workflow development using Jupyter notebooks and Airflow. Through their talk and live demo they showed how they had eliminated common bottlenecks in transitioning experiments to production — with a resulting boost to productivity, simplified debugging, and support for large-scale, distributed workflows.
This blog post recaps their session and provides resources for you to learn more.
Jupyter Notebooks: Development Heaven, Production Hell
Jupyter Notebooks have become indispensable tools for data scientists and engineers, providing a rich, interactive environment for prototyping, experimentation, and collaboration. The browser-based interface, JupyterLab, is language-agnostic and supports various runtimes, empowering users to efficiently build, test, and refine machine learning (ML) models and data workflows.
However, despite their popularity, Jupyter Notebooks often create bottlenecks when experiments need to transition from prototype to production. Data scientists rely heavily on platform and data engineers to manage the complexities of scaling workflows, including bundling code, configuring compute environments, and scheduling runs. The pain points that arise — manual intervention, disconnected workflows, and challenges with debugging large-scale experiments — all stifle productivity. The pain is especially acute during early experimentation phases where every changed variable means the process has to be repeated.
Demonstrating a Better Way
In their Summit session, Neha and Sathish ran a live demo highlighting how their team has tackled these pain points.
The demo illustrated the creation and execution of a ML workflow for sentiment analysis on iPhone customer reviews. Using Apache Airflow®, tasks such as data ingestion, feature engineering, model fine-tuning, and evaluation were orchestrated seamlessly across multiple languages and frameworks (Python, Scala, Spark) within a single workflow. By automating and parameterizing these tasks, they demonstrated how workflows could be reproduced and scaled effortlessly, eliminating the need for manual oversight.
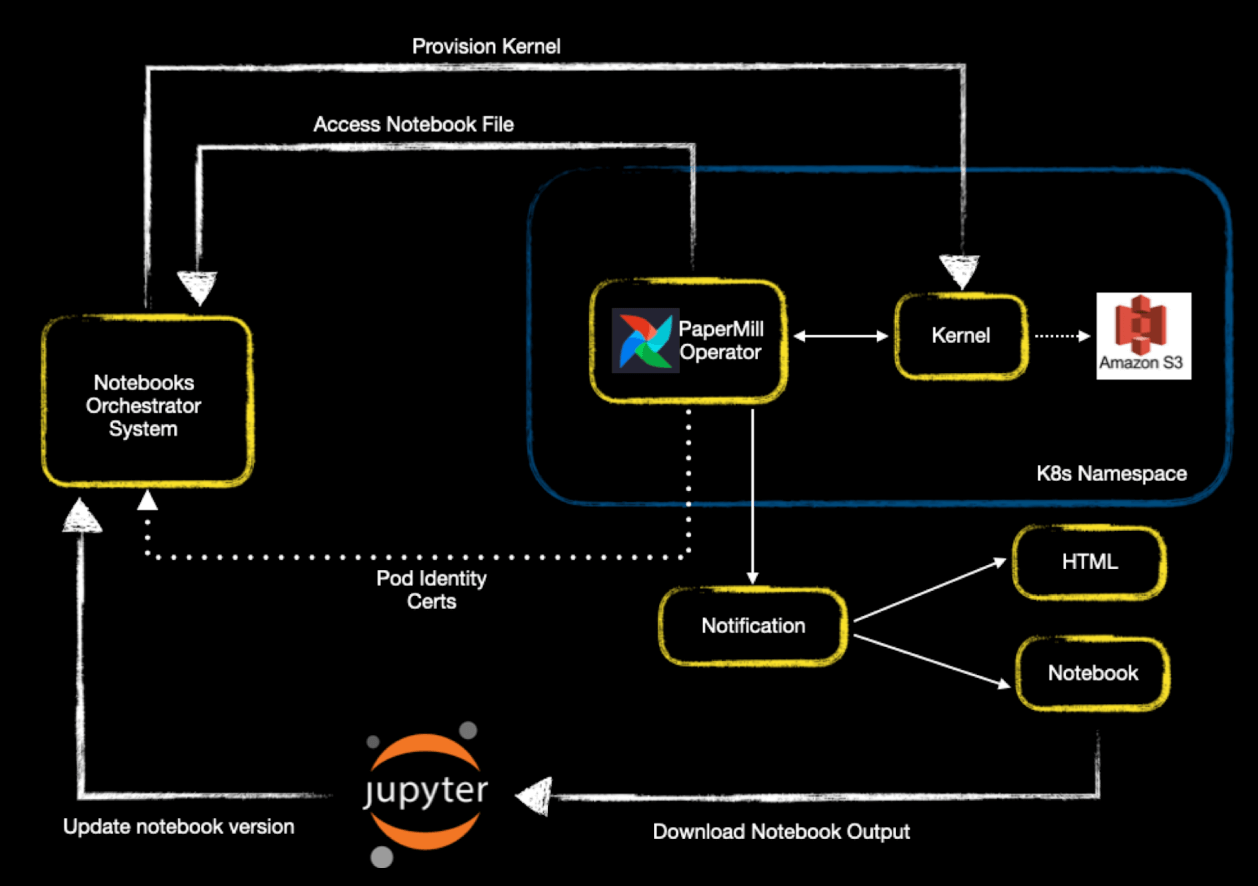
Figure 1: Jupyter notebook execution using Airflow. An Airflow worker invokes the PaperMill operator to launch the kernel and run the Notebook code and then send notifications to users. Image source.
Airflow: The Backbone of Apple’s Workflow Revolution
At the heart of Apple’s approach is Apache Airflow, a robust orchestration platform that bridges the gap between Jupyter’s interactive experimentation and the need for scalable, production-ready pipelines. Airflow’s extensibility, monitoring capabilities, and vast community support made it an ideal choice for the data platform team’s requirements.
A critical component of the solution is the Papermill operator, which enables the parameterization and execution of Jupyter Notebooks. Apple engineers extended this operator to address specific limitations:
- Language Agnosticism: Previously, the Papermill operator was tightly coupled with Python. Apple’s enhancements now support multiple languages and runtimes, including Scala and Spark, allowing data scientists to execute notebooks in their preferred environments.
- Cloud Scalability: By decoupling execution from local environments, the operator now supports remote kernels running in Kubernetes clusters, enabling large-scale, distributed workflows.
- Multi-Tenancy and Flexibility: With support for multiple versions of libraries and shared resources, data scientists can run isolated experiments without conflicts.
These enhancements, captured in the Extend papermill operator Pull Request merged in November 2023, allow notebooks to be integrated seamlessly into Airflow pipelines. Now Jupyter is extended from a prototyping tool into a cornerstone of production-grade workflows.
Results and Looking Ahead
Apple’s enhancements have delivered tangible benefits:
- Enhanced Productivity: Data scientists can now focus on experimentation without relying on platform engineers for productionizing workflows.
- Scalability: Complex workflows involving large datasets and distributed environments are handled seamlessly.
- Improved Debugging: Failures are easier to diagnose and resolve directly within the workflow, reducing resolution times.
Looking forward, the team at Apple aims to further enhance their solution by supporting event-driven notebook workflows, improving workflow sharing, and collaborating with the open-source community to expand capabilities.
Next Steps
Apple’s innovative approach to streamlining data science workflows is a testament to the power of combining Jupyter Notebooks and Apache Airflow. Watch the full session replay to see the demo in action and learn more about their contributions to the Papermill operator.
Many data science and ML engineers turn to Airflow to orchestrate data flows as part of their MLOps workflows. The best way to get started is to try it all out for free on Astro, the industry’s leading managed Airflow service.
Apple is not alone in their desire to use Airflow for ingesting data and orchestrating seamlessly across multiple languages and frameworks. That’s why we are incredibly excited about this new capability in Airflow 3.0 that allows developers to run workers in the language of their choice. Astro unlocks such capabilities with Day Zero support for upgrades to the latest version of Airflow.
